aes(x = ..., y = ..., color = ..., linetype = ...)15 Visualization
Notelearning goals
- Analyze the principles behind informative visualizations
- Incorporate visualization into an analysis workflow
- Learn to make “the design plot”: a standard visualization of experimental data
- Select different visualizations of variability and distribution
- Connect visualization concepts to measurement principles
What makes visualizations so useful, and what role do they play in the experimenter’s toolkit? Simply put, data visualization is the act of “making the invisible visible.” Our visual systems are remarkably powerful pattern detectors, and relationships that aren’t at all clear when scanning through rows of raw data can immediately jump out at us when presented in an appropriate graphical form (Zacks and Franconeri 2020). Good visualizations aim to deliberately harness this power and put it to work at every stage of the research process, from the quick sanity checks we run when first reading in our data to the publication-quality figures we design when we are ready to communicate our findings.
Yet, our powerful pattern detectors can also be a liability; if we’re not careful, we can easily be fooled into seeing patterns that are unreliable or even misleading. As psychology moves into an era of bigger data and more complex behaviors, we become increasingly reliant on data visualization literacy (Börner, Bueckle, and Ginda 2019) to make sense of what is going on. Further, as a researcher reporting about your data, creating appropriate visualizations that are aligned with your analyses (as well as your design and preregistration) is an important part of transparency and bias reduction in your reporting.
Notecase study
Mapping a pandemic
In 1854, a deadly outbreak of cholera was sweeping through London. The scientific consensus at the time was that diseases like cholera spread through breathing poisonous and foul-smelling vapors, an idea known as the “miasma theory” (Halliday 2001). An obstetrician and anesthesiologist named John Snow proposed an alternative theory:
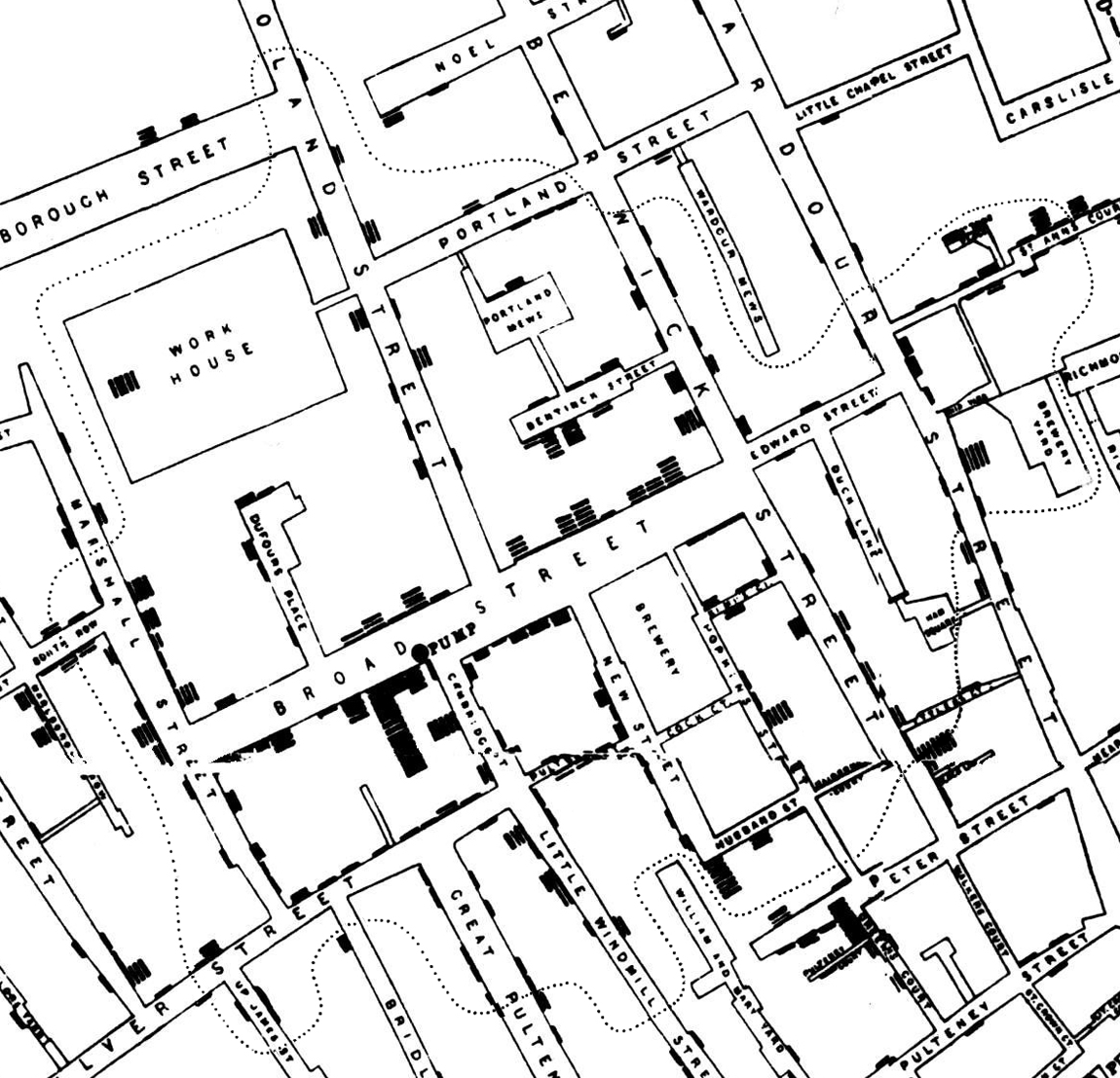
rather than spreading through foul air, he thought that cholera was spreading through a polluted water supply (Snow 1855). To make a public case for this idea, he started counting cholera deaths. He marked each case on a map of the area and indicated the locations of the water pumps for reference. Furthermore, a line could be drawn representing the region that was closest to each water pump, a technique that is now known as a Voronoi diagram. The resulting illustration clearly reveals that cases clustered around an area called Golden Square, which received water from a pump on Broad Street (figure 15.1). Although the precise causal role of these maps in Snow’s own thinking is disputed, and it is likely that he produced them well after the incident (Brody et al. 2000), they nonetheless played a significant role in the history of data visualization (Friendly and Wainer 2021).
Nearly two centuries later, as the COVID-19 pandemic swept through the world, governmental agencies like the Centers for Disease Control and Prevention (CDC) produced maps of the outbreak that became much more familiar (figure 15.2).
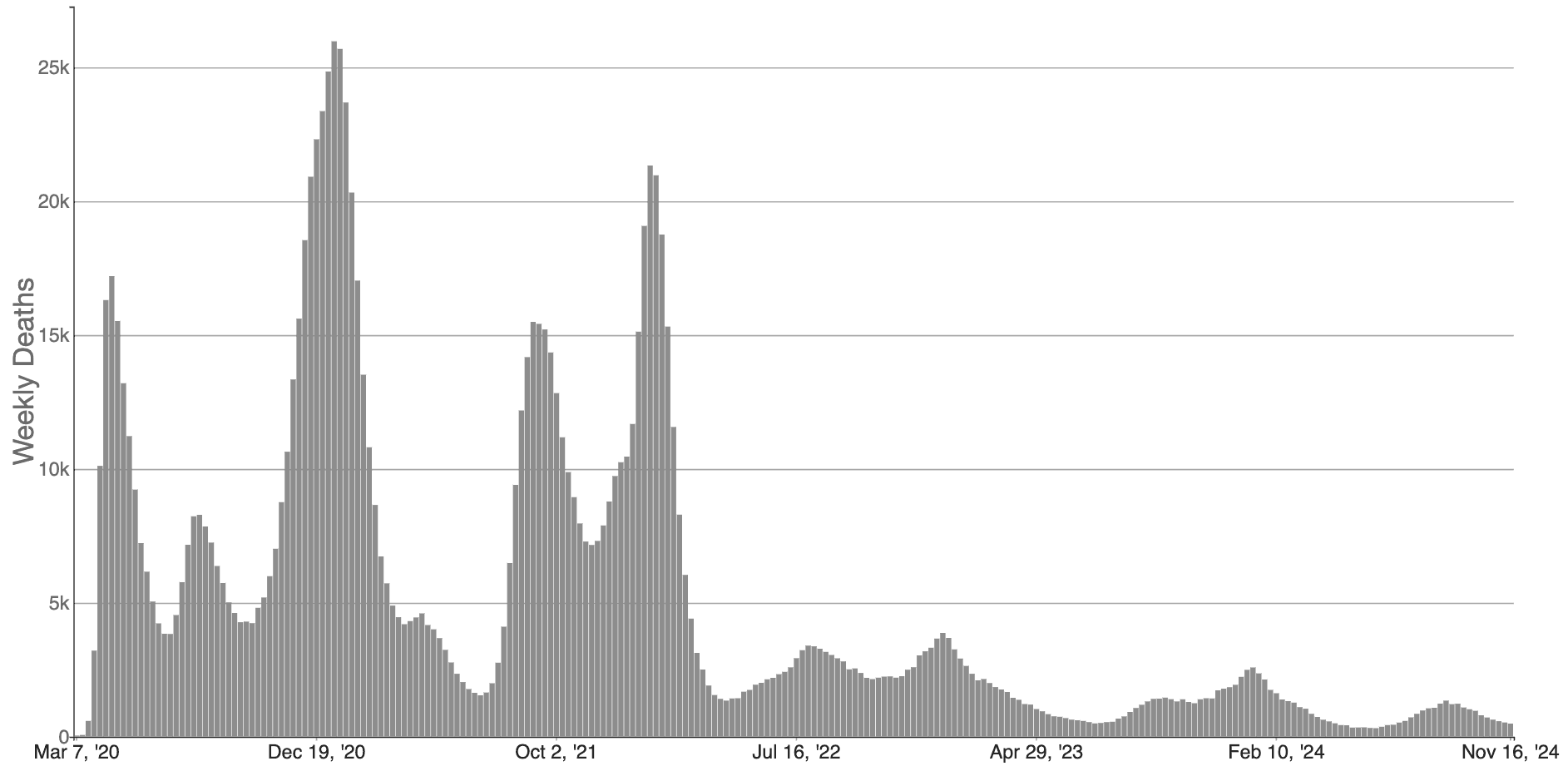
These maps make abstract statistics visible: By assigning higher cumulative deaths rates to darker colors, we can see at a glance which areas have been most affected. And we’re not limited by the spatial layout of a map. We’re now also used to seeing the horizontal axis correspond to time and the vertical axis correspond to some value at that time. Curves like the following, showing the weekly counts of new deaths, allow us to see other patterns, like the rate of change. Even though more and more cases accumulate every day, we can see at a glance the different “waves” of cases and when they peaked (figure 15.3).
While these visualizations capture purely descriptive statistics, we often want our visualizations to answer more specific questions. For example, we may ask about the effectiveness of vaccinations: How do case rates differ across vaccinated and unvaccinated populations? In this case, we may talk about “breaking out” a curve by some other variable, like vaccination status (figure 15.4).
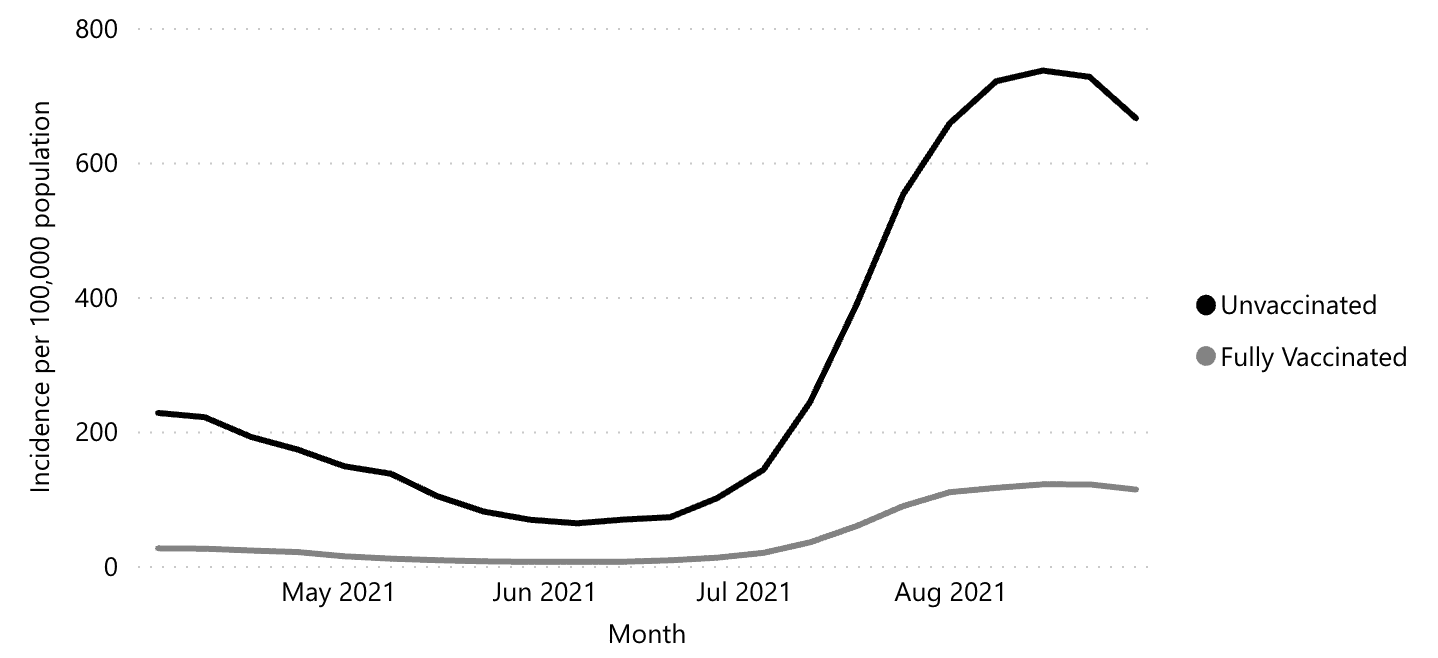
From this visualization, we can see that unvaccinated individuals are about six times more likely to test positive. At the same time, these visualizations were produced using observational data, which makes it challenging to draw causal inferences. For example, people were not randomly assigned to vaccination conditions, and those who have avoided vaccinations may differ in other ways than those who sought out vaccinations. Additionally, you may have noticed that these visualizations typically do not give a sense of the raw data, the sample sizes of each group, or uncertainty about the estimates. In this chapter, we will explore how to use visualizations to communicate the results of carefully controlled psychology experiments, which license stronger causal inferences.
15.1 Basic principles of (confirmatory) visualization
In this section, we begin by introducing a few simple guidelines to keep in mind when making informative visualizations in the context of experimental psychology.1 Remember that our needs may be distinct from other fields, such as journalism or public policy. You may have seen beautiful and engaging full-page graphics with small print and a wealth of information. The art of designing and producing these graphics is typically known as infoviz and should be distinguished from what we call statistical visualization (Gelman and Unwin 2013).
1 For the purposes of understanding the examples in this chapter, it should be sufficient to work through the tutorials on data manipulation and visualization in appendix D and appendix E.
Roughly, infoviz aims to construct rich and immersive worlds to visually explore: a reader can spend hours pouring over the most intricate graphics and continue to find new and intriguing patterns. Statistical visualization, on the other hand, aims to crisply convey the logic of a specific inference at a glance. These visualizations are the production-ready figures that anchor the results section of a paper and accompany the key, preregistered analyses of interest. In this section, we review several basic principles of making statistical visualizations. We then return below to the role of visualization in more exploratory analyses.
15.1.1 Principle 1: Show the design
There are so many different kinds of graphs (bar graphs, line graphs, scatter plots, and pie charts) and so many different possible attributes of those graphs (colors, sizes, line types). How do we begin to decide how to navigate these decisions? The first principle guiding good statistical visualizations is to show the design of your experiment.
The first confirmatory plot you should have in mind for your experiment is the design plot. Analogous to the “default” or “saturated” model in chapter 7, the design plot should show the key dependent variable of the experiment, broken down by all of the key manipulations. Critically, design plots should neither omit particular manipulations because they didn’t yield an effect or include extra covariates because they seemed interesting after looking at the data. Both of these steps are the visual analogue of \(p\)-hacking! Instead, the design plot is the “preregistered analysis” of your visualization: it illustrates a first look at the estimated causal effects from your experimental manipulations. In the words of Coppock (2019), “Visualize as You Randomize”!
It can sometimes be a challenge to represent the full pattern of manipulations from an experiment in a single plot. Below we give some tricks for maximizing the legible information in your plot. But if you have tried these and the design plot still looks crowded and messy, that may indicate that your experiment is manipulating too many things at once!
There are strong (unwritten) conventions about how your confirmatory analysis is expected to map onto graphical elements, and following these conventions can minimize confusion. Start with the variables you manipulate, and make sure they are clearly visible. Conventionally, the primary manipulation of interest (e.g., condition) goes on the x-axis, and the primary measurement of interest (e.g., responses) goes on the y-axis. Other critical variables of interest (e.g., secondary manipulations and demographics) are then assigned to other “visual variables” (e.g., color, shape, or size).
Notecode
The visualization library ggplot2 (see appendix E) makes the mapping of variables in the data to visual data. Part of a ggplot call is an aes() (short for aesthetics) mapping:
The aesthetics argument serves as a statement of how data are mapped to “marks” on the plot. This transparent mapping makes it very easy to explore different plot types by changing that aes() statement, as we’ll see below.
As an example, we will consider the data from Stiller, Goodman, and Frank (2015) that we explored back in chapter 7. Because this experiment was a developmental study, the primary independent variable of interest was the age group of participants (ages two, three, or four). So age gets assigned to the horizontal (x) axis. The dependent variable is accuracy: the proportion of trials that a participant made the correct response (out of four trials). So accuracy goes on the vertical (y) axis. Now, we have two other variables that we might want to show: the condition (experimental vs control) and the type of stimuli (houses, beds, and plates of pasta). When we think about it, though, only condition is central to exposing the design. While we might be interested in whether some types of stimuli are systematically easier or harder than others, condition is more central for understanding the logic of the study.
Notecode
As a reminder, here’s our code for loading the Stiller, Goodman, and Frank (2015) data:
repo <- "https://github.com/langcog/experimentology/raw/main"
sgf <- read_csv(file.path(repo, "data/tidyverse/stiller_scales_data.csv")) |>
mutate(age_group = cut(age, 2:5, include.lowest = TRUE),
condition = fct_recode(condition,
"Experimental" = "Label", "Control" = "No Label"))
sgf_means <- sgf |> group_by(condition, age_group) |> summarize(rating = mean(correct))15.1.2 Principle 2: Facilitate comparison
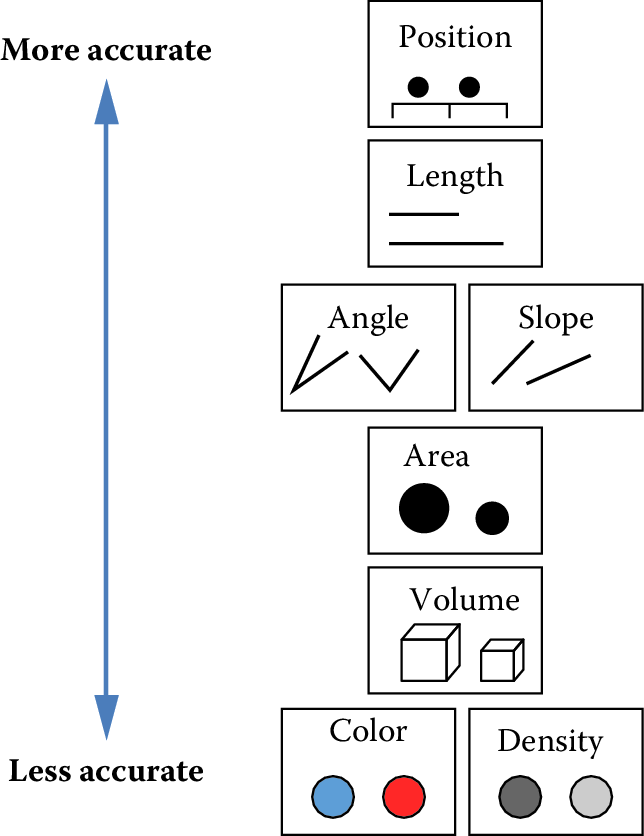
Now that you’ve mapped elements of your design to the figure’s axes, how do you decide which graphical elements to display? You might think: well, in principle, these assignments are all arbitrary anyway. As long as we clearly label our choices, it shouldn’t matter whether we use lines, points, bars, colors, textures, or shapes. It’s true that there are many ways to show the same data. But being thoughtful about our choices can make it much easier for readers to interpret our findings.
The second principle of statistical visualizations is to facilitate comparison along the dimensions relevant to our scientific questions. It is easier for our visual system to accurately compare the location of elements (e.g., noticing that one point is a certain distance away from another) than to compare their areas or colors (e.g., noticing that one point is bigger or brighter than another). Figure 15.5 shows an ordering of visual variables based on how accurate our visual system is in making comparisons.
For example, we could start by plotting the accuracy of each age group as colors (figure 15.6).
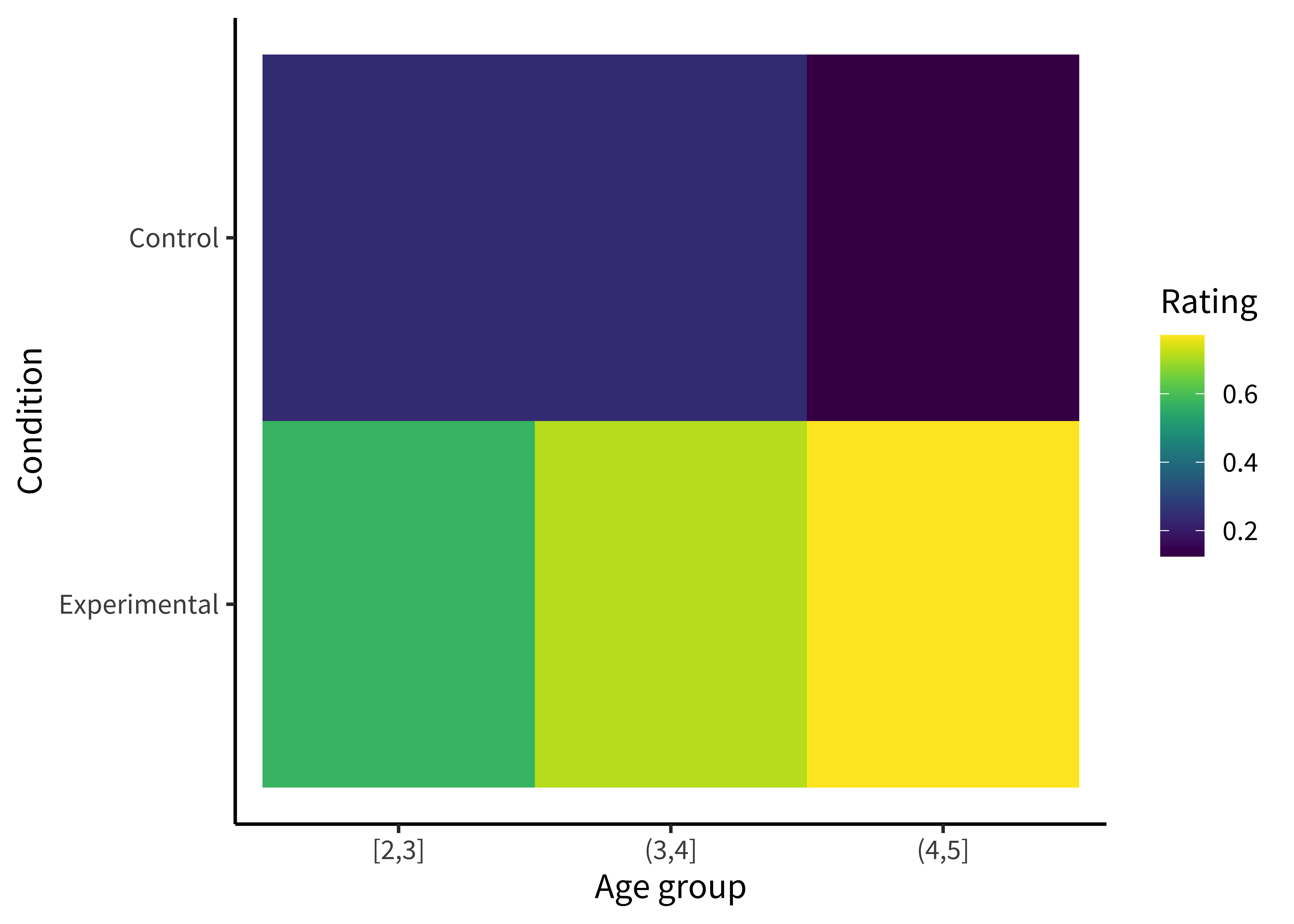
Notecode
To make this (bad) visualization, we used a ggplot function called geom_tile().
ggplot(sgf_means, aes(x = age_group, y = condition, fill = rating)) +
geom_tile() +
labs(x = "Age group", y = "Condition", fill = "Rating")Or we could plot the accuracies as sizes/areas (figure 15.7).
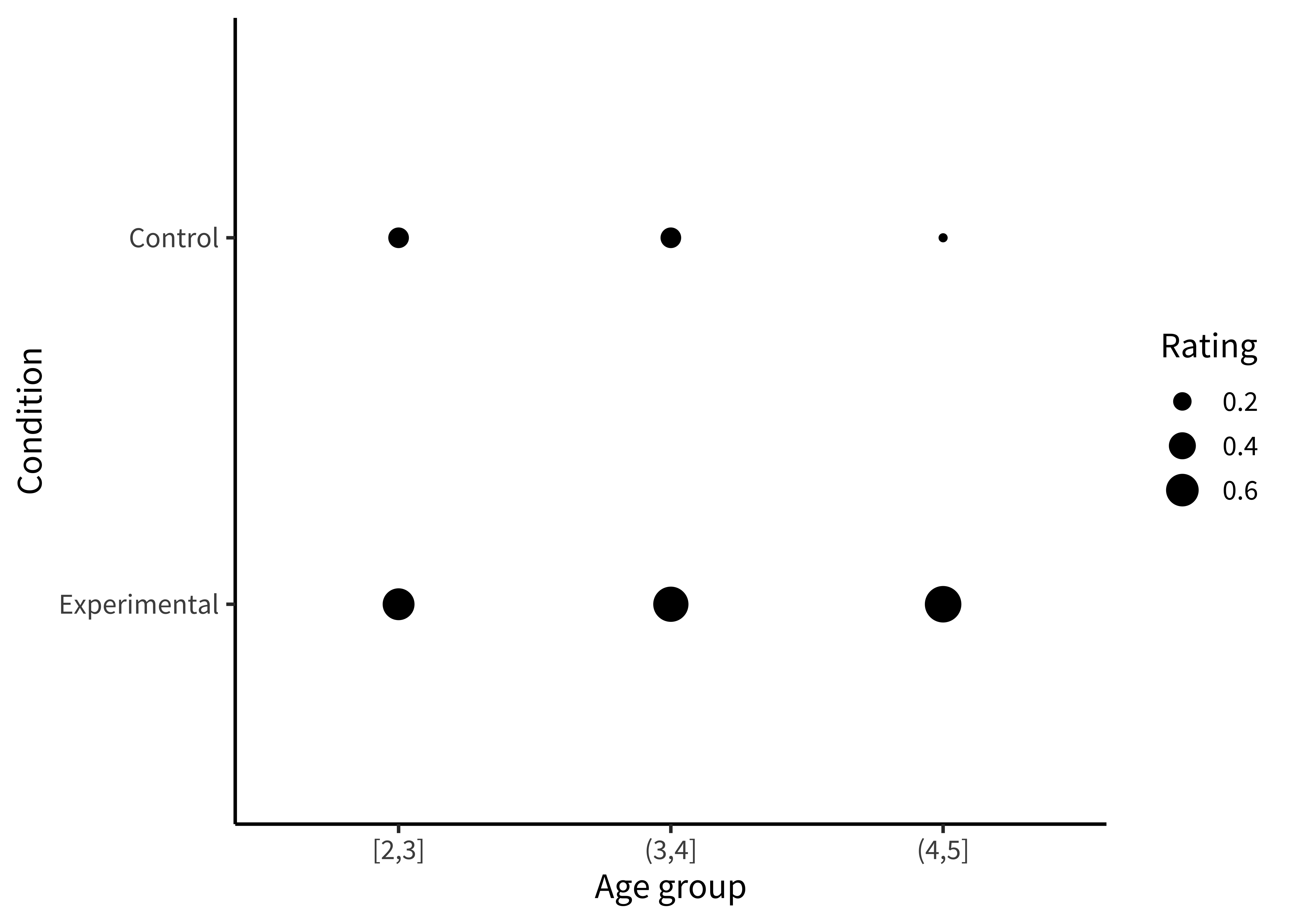
Notecode
To make this (also bad) visualization, we mapped the rating to the size aesthetic in our aes() call.
ggplot(sgf_means, aes(x = age_group, y = condition, size = rating)) +
geom_point() +
labs(x = "Age group", y = "Condition", size = "Rating")These plots allow us to see that one condition is (qualitatively) bigger than others, but it’s hard to tell how much bigger. Additionally, this way of plotting the data places equal emphasis on age and condition, but we may instead have in mind particular contrasts, like the change across ages and how that change differs across conditions. An alternative is to show six bars: three on the left showing the “experimental” phase and three on the right showing the “control” phase. Maybe the age groups then are represented as different colors, as in figure 15.8.
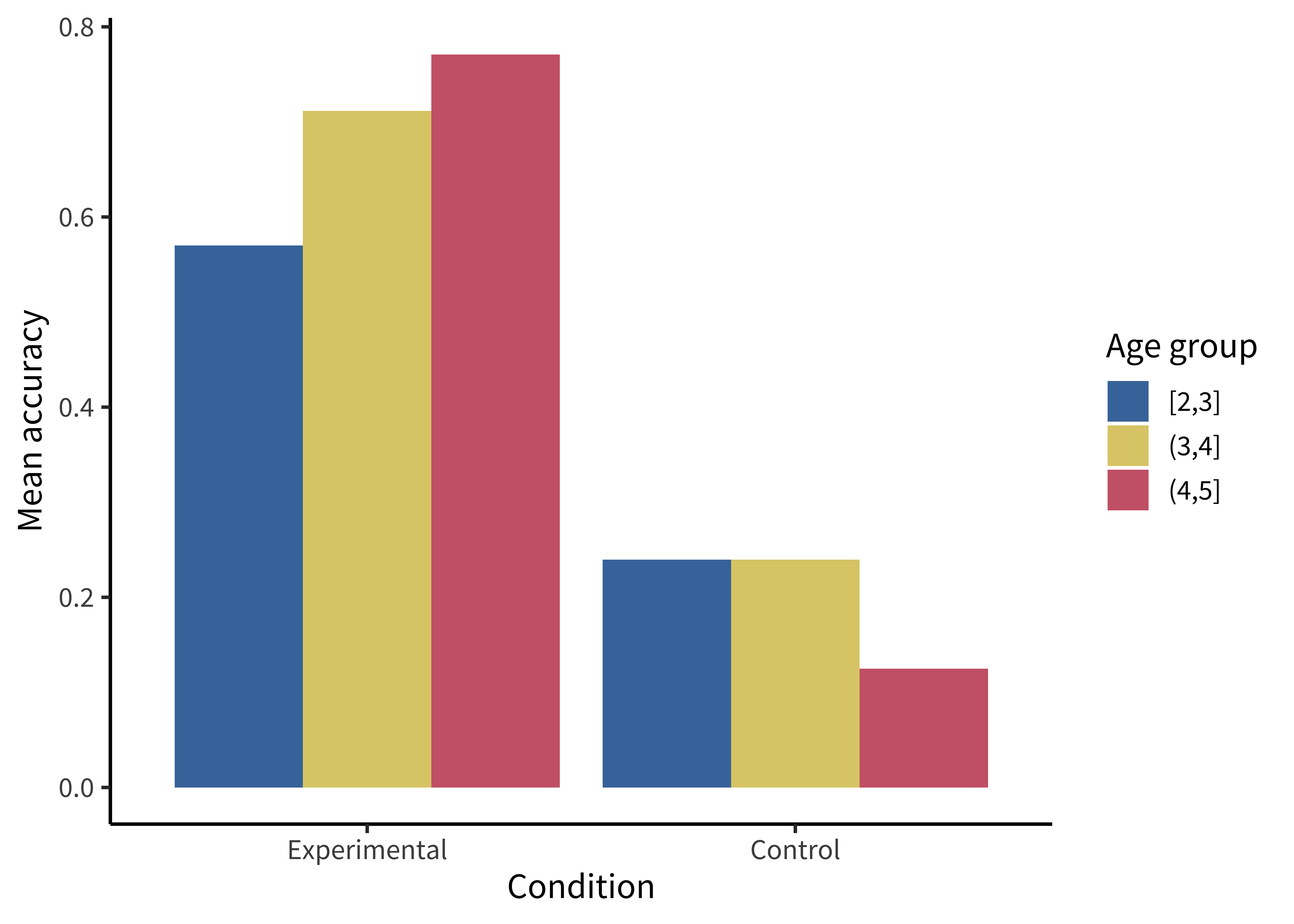
Notecode
We make bar plots using geom_col(). By default, it creates “stacked” bar plots, where all values associated with the same x value (here, condition) get stacked up on top of one another. Stacked bar plots can be useful if, for example, you’re plotting proportions that sum up to 1, or want to show how some big count is broken down into subcategories. But the more common bar plot used in psychology puts the bars next to one another, or “dodges” them. To accomplish this, we use the position = "dodge" argument:
ggplot(sgf_means, aes(x = condition, y = rating, fill = age_group)) +
geom_col(position = "dodge") +
labs(x = "Condition", y = "Mean accuracy", fill = "Age group")This plot is slightly better: it’s easier to compare the heights of bars than the “blueness” of squares, and mapping age to color draws our eye to those contrasts. However, we can do even better by noticing that our experiment was designed to test an interaction. That statistic of interest is a difference of differences. To what extent does the developmental change in performance on the experimental condition differ from developmental change in performance on the control condition? Some researchers have gotten proficient at reading off interactions from bar plots, but they also require a complex set of eye movements. We have to look at the pattern across the bars on the left, and then jump over to the bars on the right, and implicitly judge one difference against the other: the actual statistic isn’t explicitly shown anywhere! What could help facilitate this comparison? Consider the line plot in figure 15.9.
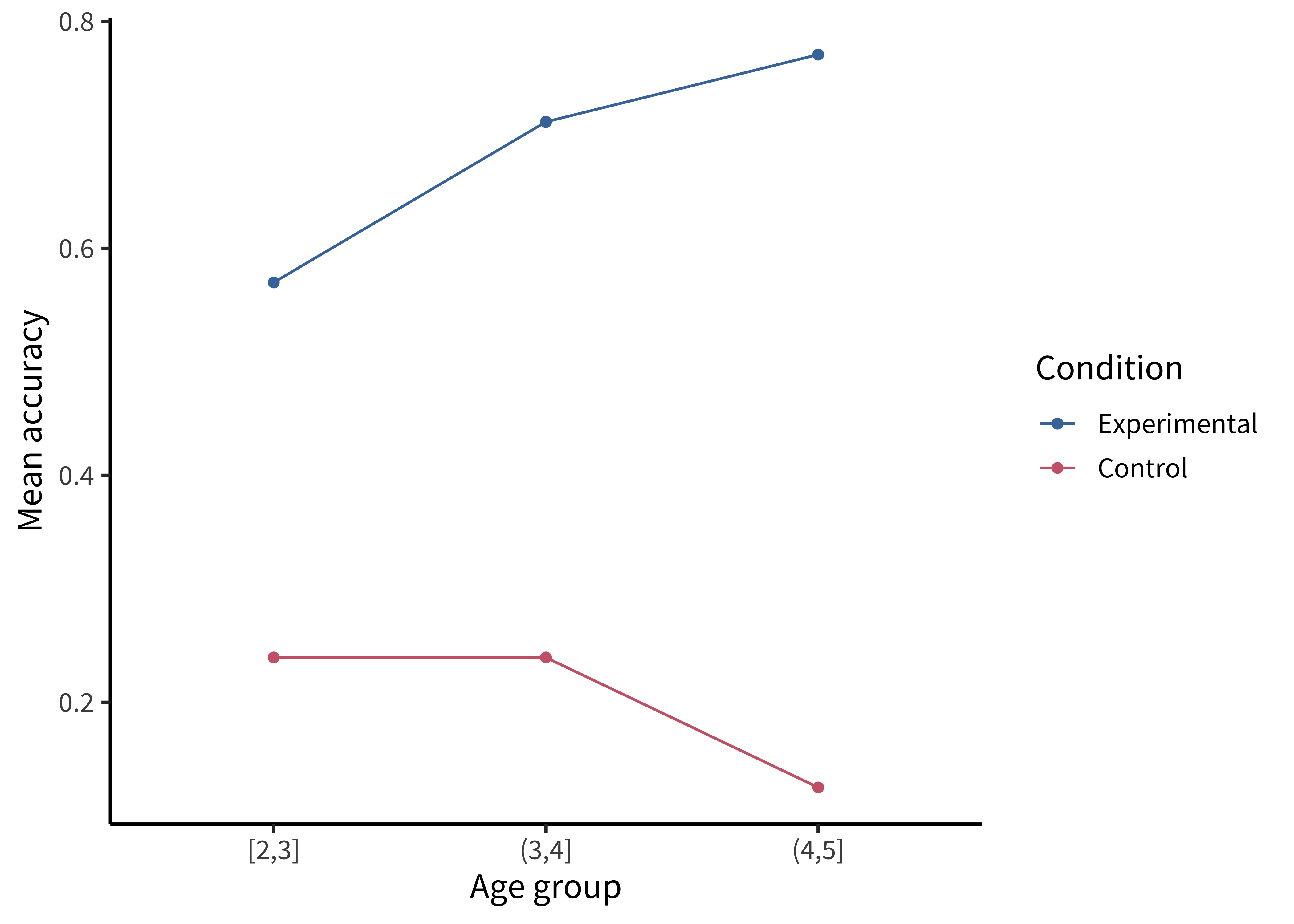
Notecode
Using a combination of geom_point() and geom_line():
ggplot(sgf_means, aes(x = age_group, y = rating, color = condition)) +
geom_point() + geom_line(aes(group = condition)) +
labs(x = "Age group", y = "Mean accuracy", color = "Condition")The interaction contrast we want to interpret is highlighted visually in this plot. It is much easier to compare slopes of lines than mentally compute a difference of differences between bars. Here are a few corollaries of this principle (adapted from a presentation by Karl Broman).
It is easier to compare values that are adjacent to one another. This is especially important when there are many different conditions included on the same plot. If particular sets of conditions are of theoretical interest, place them close to one another. Otherwise, sort conditions by a meaningful value (rather than alphabetically, which is usually the default for plotting software).
When possible, color-code labels and place them directly next to data rather than in a separate legend. Legends force readers to glance back and forth to remember what different colors or lines mean.
When making histograms or density plots, it is challenging to compare distributions when they are placed side by side. Instead, facilitate comparison of distributions by vertically aligning them, or making them transparent and placed on the same axes.
If the scale makes it hard to see important differences, consider transforming the data (e.g., taking the logarithm).
When making bar plots, be very careful about the vertical y-axis. A classic “misleading visualization” mistake is to cut off the bottom of the bars by placing the endpoint of the y-axis at some arbitrary value near the smallest data point. This is misleading because people interpret bar plots in terms of the relative area of the bars (i.e., the amount of ink taken up by the bar), not just their absolute y-values.
If a key variable from your design is mapped to color, choose the color scale carefully. For example, if the variable is binary or categorical, choose visually distinct colors to maximize contrast (e.g., black, blue, and orange). If the variable is ordinal or continuous, use a color gradient. If there is a natural midpoint (e.g., if some values are negative and some are positive), consider using a diverging scale (e.g., different colors at each extreme). Remember also that a portion of your audience may be colorblind.2
2 Palettes like viridis have been designed to be colorblind-friendly and also perceptually uniform (i.e., the perceived difference between 0.1 and 0.2 is approximately the same as the difference between 0.8 and 0.9).
15.1.3 Principle 3: Show the data
Looking at older papers, you may be alarmed to notice how little information is contained in the graphs. The worst offenders might show just two bars, representing average values for two conditions. This kind of plot adds very little beyond a sentence in the text reporting the means, but it can also be seriously misleading. It hides real variation in the data, making a noisy effect based on a few data points look the same as a more systematic one based on a larger sample. Additionally, it collapses the distribution of the data, making a multimodal distribution look the same as a unimodal one. The third principle of modern statistical visualization is to show the data and visualize variability in some form.
The most minimal form of this principle is to always include error bars.3 Error bars turn a purely descriptive visualization into an inferential one. They represent a minimal form of uncertainty about the possible statistics that might have been observed, not just the one that was actually observed. Figure 15.10 shows the data with (bootstrapped) error bars.
3 And be sure to tell the reader what the error bars represent—a 95% confidence interval? A standard error of the mean?—without this information, error bars are hard to interpret (see the Depth box below).
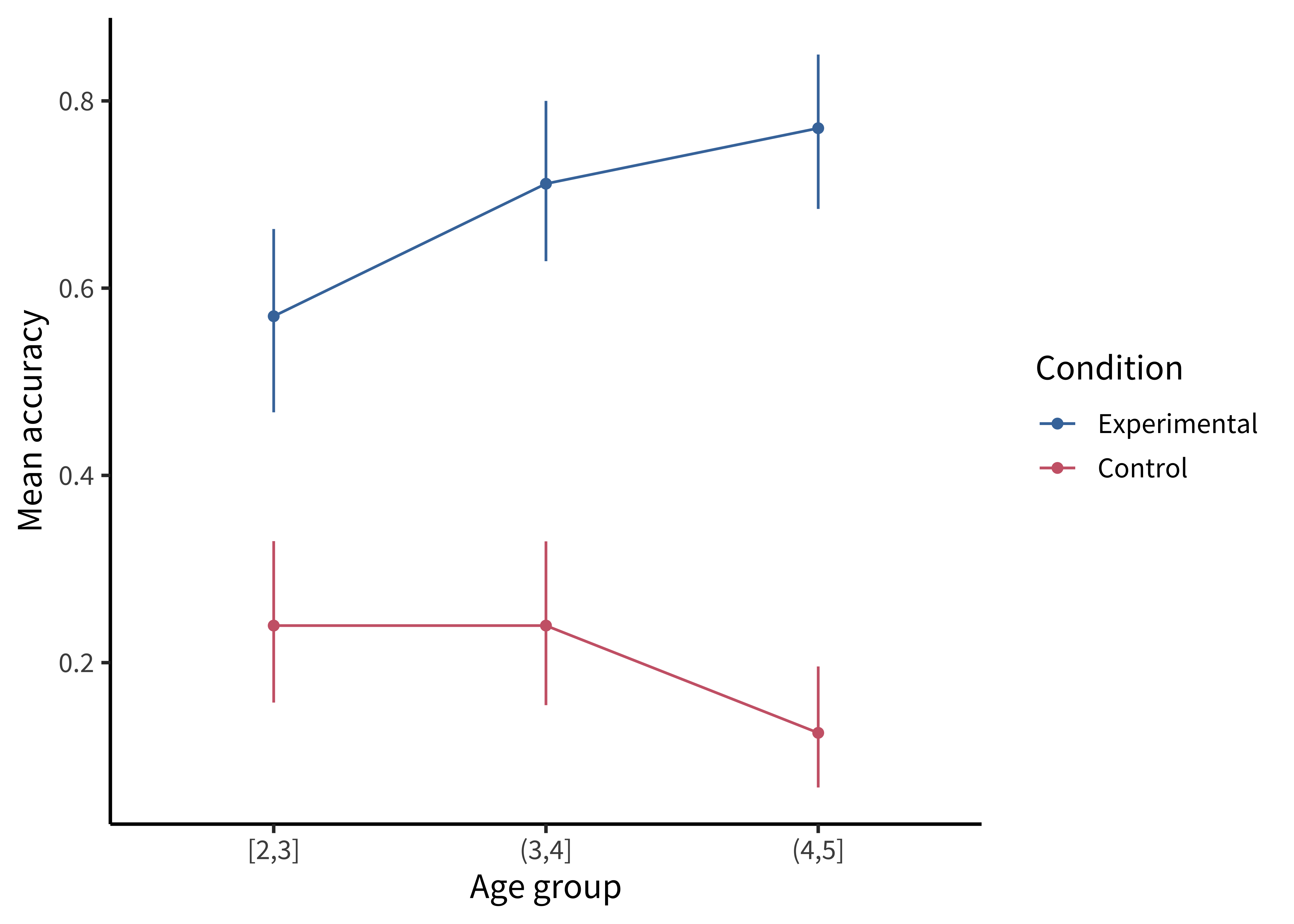
Notecode
Confidence intervals can come from a variety of methods, as discussed in chapter 6 and chapter 7. Here we use bootstrapped CIs for illustration:
sgf_boot <- sgf |>
group_by(condition, age_group) |>
tidyboot::tidyboot_mean(column = correct)There are several geoms that can be used to show error bars, including geom_errorbar() and geom_linerange(). Here we use geom_pointrange() to compactly show both the points and associated error bars:
ggplot(sgf_boot, aes(x = age_group, y = empirical_stat, color = condition)) +
geom_pointrange(aes(ymin = ci_lower, ymax = ci_upper)) +
geom_line(aes(group = condition)) +
labs(x = "Age group", y = "Mean accuracy", color = "Condition")But we can do even better. By overlaying the distribution of the actual data points on the same plot, we can give the reader information about not just the statistical inferences but also the underlying data supporting those inferences. In the case of the Stiller, Goodman, and Frank (2015) study, data points for individual trials are binary (correct or incorrect). It’s technically possible to show individual responses as dots at 0s and 1s, but this doesn’t tell us much (we’ll just get a big clump of 0s and a big clump of 1s). The question to ask yourself when “showing the data” is: What are the theoretically meaningful units of variation in the data? This question is closely related to our discussion of mixed-effects models in chapter 7, when we considered which random effects we should include. Here, a reader is likely to wonder how much variance was found across different children in a given age group. To show such variation, we aggregate to calculate an accuracy score for each participant.4
4 While participant-level variation is a good default, the relevant level of aggregation may differ across designs. For example, collective behavior studies may choose to show the data point for each group. This choice of unit is also important when generating error bars: if you have a small number of participants but many observations per participant, you are faced with a choice. You may either bootstrap over the flat list of all individual observations (yielding very small error bars), or you may first aggregate within participants (yielding larger error bars that account for the fact that repeated observations from the same participant are not independent).
There are many ways of showing the resulting distribution of participant-level data. For example, a boxplot shows the median (a horizontal line) in the center of a box extending from the lower quartile (25%) to the upper quartile (75%). Lines then extend out to the biggest and smallest values (excluding outliers, which are shown as dots).
Figure 15.11 gives the boxplots for the Stiller data, which don’t look that informative—perhaps because of the coarseness of individual participant averages due to the small number of trials.
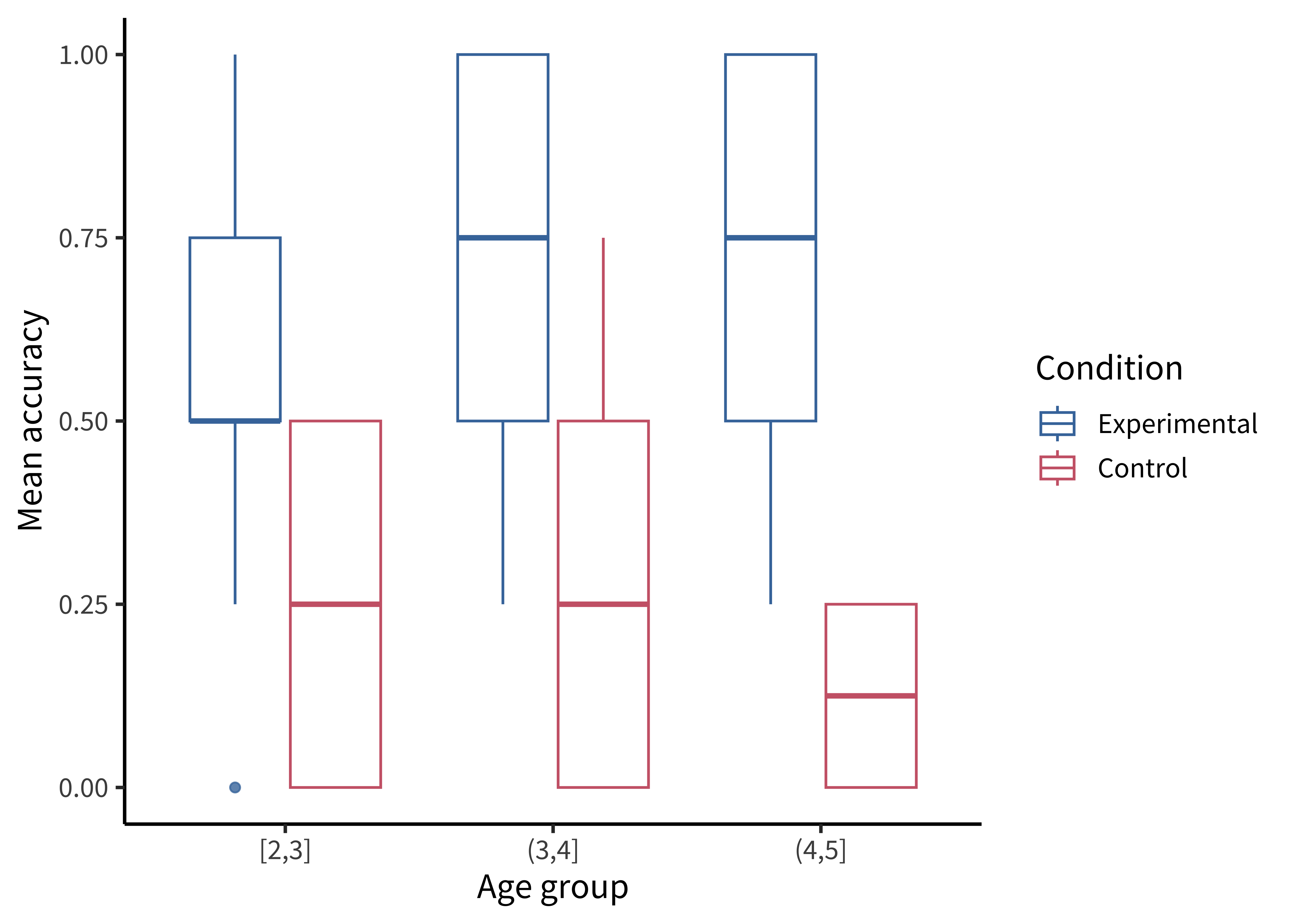
Notecode
First we compute participant-level accuracies, then we can make a box plot using geom_boxplot():
sgf_subj_means <- sgf |>
group_by(condition, age_group, subid) |>
summarize(rating = mean(correct))
ggplot(sgf_subj_means, aes(x = age_group, y = rating, color = condition)) +
geom_boxplot(alpha = 0.8) +
labs(x = "Age group", y = "Mean accuracy", color = "Condition")A common problem to run into is that geom_boxplot() requires the variable assigned to x to be discrete. If you have discrete levels of a numeric variable (e.g., age groups), make sure you’ve actually converted that variable to a factor. Otherwise, if it’s still coded as numeric, ggplot will collapse all of the levels together!
It is also common to show the raw data as jittered values with low transparency. In figure 15.12, we jitter the points because many participants have the same numbers (e.g., 50%), and if they overlap it is hard to see how many points there are.
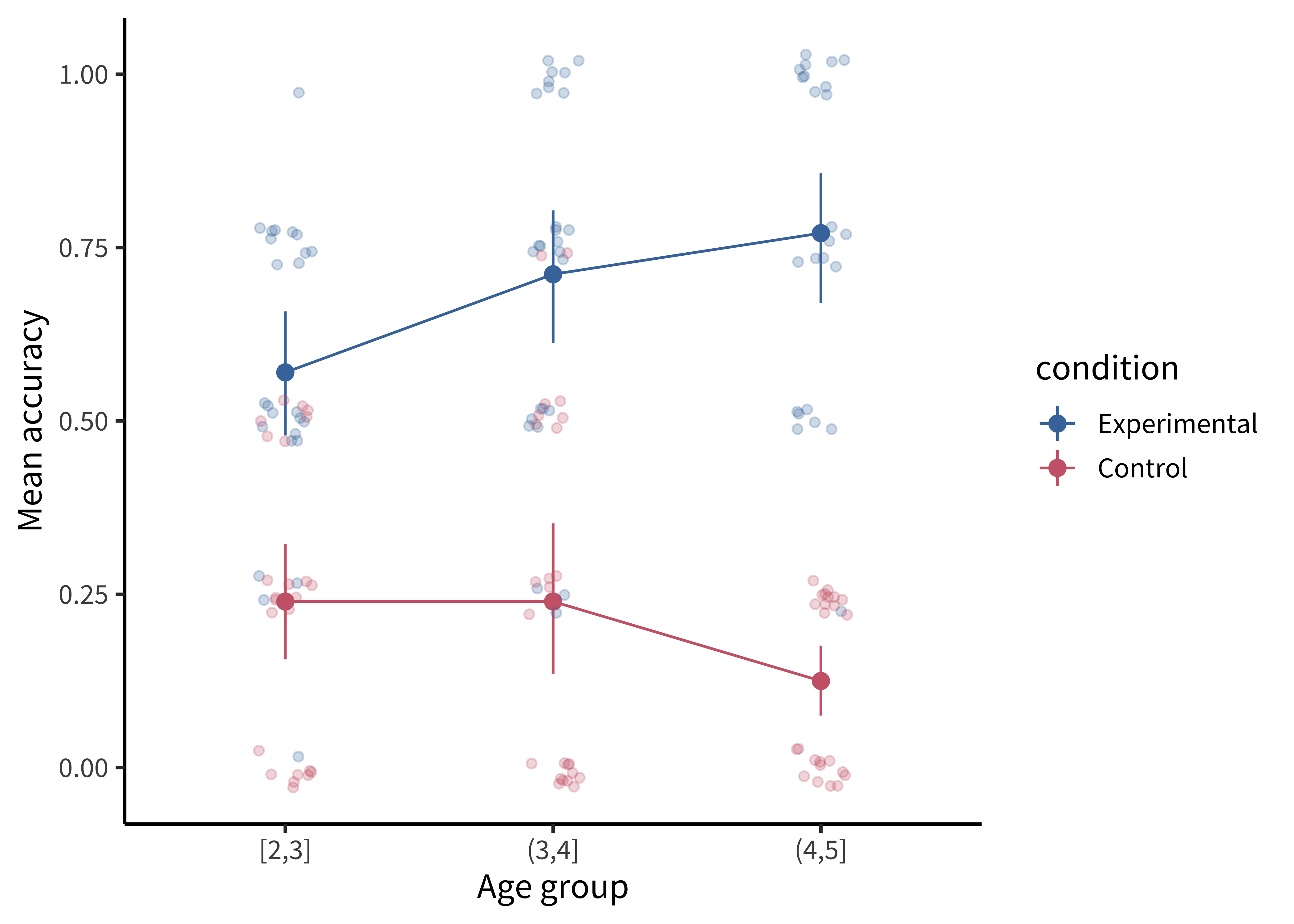
Notecode
Adding the jittered points is simple using geom_jitter(), but we are starting to have a fairly complex plot, so maybe it’s worth taking stock of how we get there.
To plot both condition means and participant means, we need to create two different data frames. Here sgf_subj_means is a data frame of means for each participant; sgf_subj_ci is a data frame with means and confidence intervals across participants. For this purpose, we use the tidyboot package (Braginsky and Yurovsky 2018) and the tidyboot_mean() function, which gives us bootstrapped 95% confidence intervals for the means.
sgf_subj_means <- sgf |>
group_by(condition, age_group, subid) |>
summarize(rating = mean(correct))
sgf_subj_ci <- sgf_subj_means |>
group_by(condition, age_group) |>
tidyboot::tidyboot_mean(rating) |>
rename(rating = empirical_stat)
ggplot(sgf_subj_ci, aes(x = age_group, y = rating, color = condition)) +
geom_pointrange(aes(ymin = ci_lower, ymax = ci_upper)) +
geom_line(aes(group = condition)) +
geom_jitter(data = sgf_subj_means, alpha = 0.25, width = 0.1, height = .03) +
labs(x = "Age group", y = "Mean accuracy", color = "Condition") The most noteworthy aspect of this code is that geom_jitter() isn’t just using a different aesthetic; it also takes a different dataframe altogether! Mixing dataframes can be an important tool for creating complex plots.
Perhaps the format that takes this principle the furthest is the so-called raincloud plot (Allen et al. 2019) shown in figure 15.13. A raincloud plot combines the raw data (“rain”) with a smoothed density (“cloud”) and a boxplot giving the median and quartiles of the distribution.
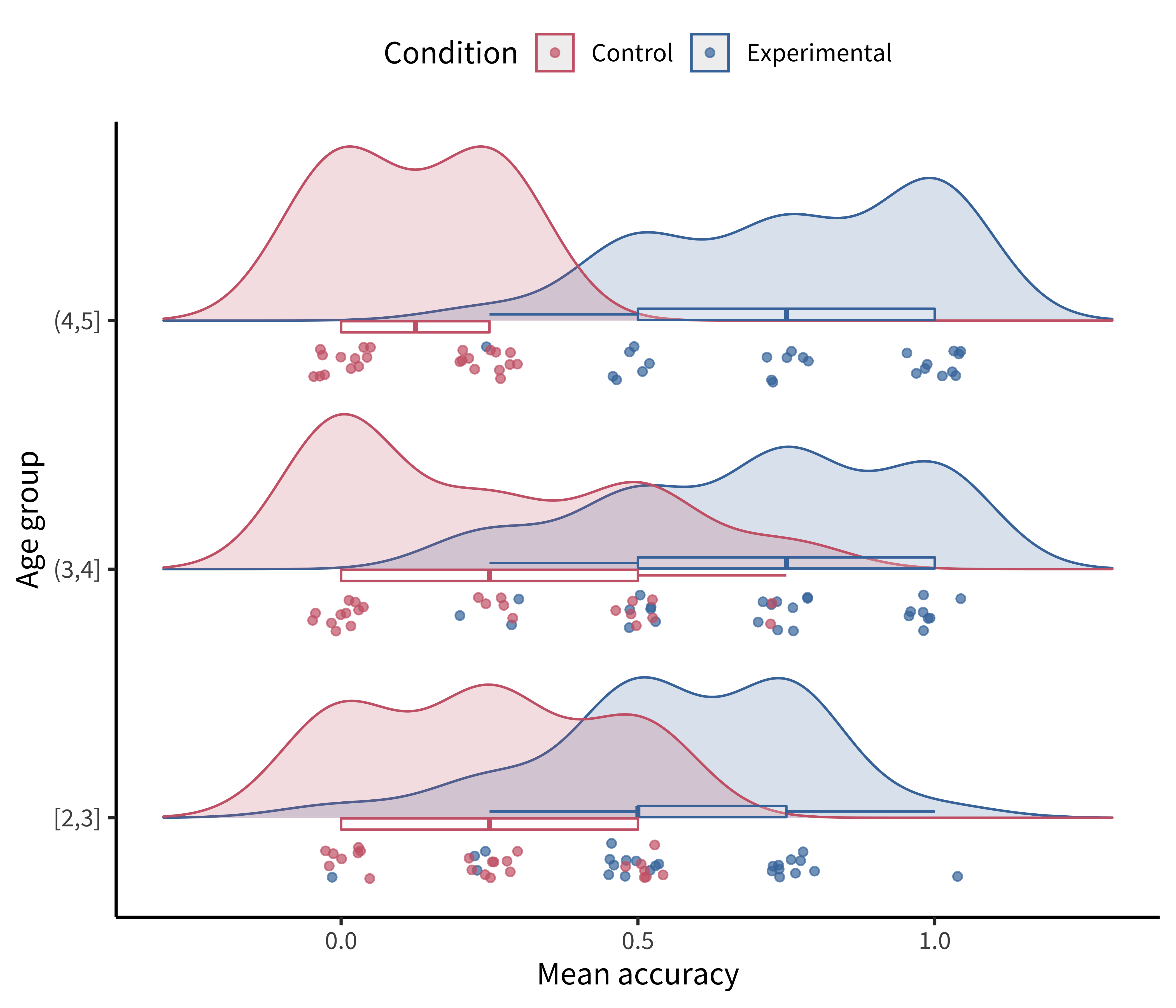
Notecode
This raincloud plot requires two additional plotting packages: ggridges (Wilke 2023) for the densities and ggstance (Henry, Wickham, and Chang 2022) for the horizontal boxplots.
library(ggridges)
library(ggstance)
ggplot(sgf_subj_means, aes(y = age_group, x = rating, color = condition)) +
geom_density_ridges(
# density plots ("clouds") staggered by condition
aes(fill = condition), alpha = 0.2, scale = 0.7,
# with jittered points ("rain")
jittered_points = TRUE, point_alpha = 0.7,
# position adjustments specifically for geom_density_ridges()
position = position_raincloud(width = 0.05, height = 0.15, ygap = 0.1)
) +
# horizontal boxplots (with outliers hidden)
geom_boxploth(width = 0.1, alpha = 0.2, outlier.shape = NA, show.legend = FALSE) +
# some customization for axes and legends
scale_y_discrete(expand = expansion(mult = c(0.2, 0.4))) +
guides(fill = "none", color = guide_legend(reverse = TRUE)) +
labs(x = "Mean accuracy", y = "Age group", color = "Condition") +
theme(legend.position = "top")
Notedepth
Visualizing uncertainty with error bars
One common misconception is that error bars are a measure of variance in the data, like the standard deviation of the response variable. Instead, they typically represent a measure of precision extracted from the statistical model. In older papers, for example, it was common to use the standard error of the mean (SEM; see chapter 6). Remember that this is not the standard deviation of the data distribution but of the sampling distribution of the mean that is being estimated. Given the central limit theorem, which tells us that this sampling distribution is asymptotically normal, it was straightforward to estimate the standard error analytically using the empirical standard deviation of the data divided by the square root of the sample size: sd(x) / sqrt(length(x)). Error bars based on the SEM often looked misleadingly small, as they only represent a 68% interval of the sampling distribution and go to zero quickly as a function of sample size. As a result, it became more common to show the 95% confidence interval instead: \([-1.96 \times \text{SEM}, 1.96 \times \text{SEM}]\).
While these analytic equations remain common, an increasingly popular alternative is to bootstrap confidence intervals (see the Depth box in chapter 6 for more on bootstrapping). The bootstrap is a powerfully generic technique, especially when you want to show error bars for summary statistics that are more complex than means, where we do not have such convenient asymptotic guarantees and “closed-form” equations. An example would be if you’re working with a skewed response variable or a dataset with clear outliers and you want to estimate medians and quartiles.
Or, suppose you want to estimate proportions from categorical data, or a more ad hoc statistic like the AUC (area underneath the curve) in a hierarchical design where it is not clear how to aggregate across items or participants in a mixed-effects model. Analytic estimators of confidence intervals can in principle be derived for these statistics, subject to different assumptions, but it is often more transparent and reliable in practice to use the bootstrap. As long as you can write a code snippet to compute a value from a dataset, you can use the bootstrap.
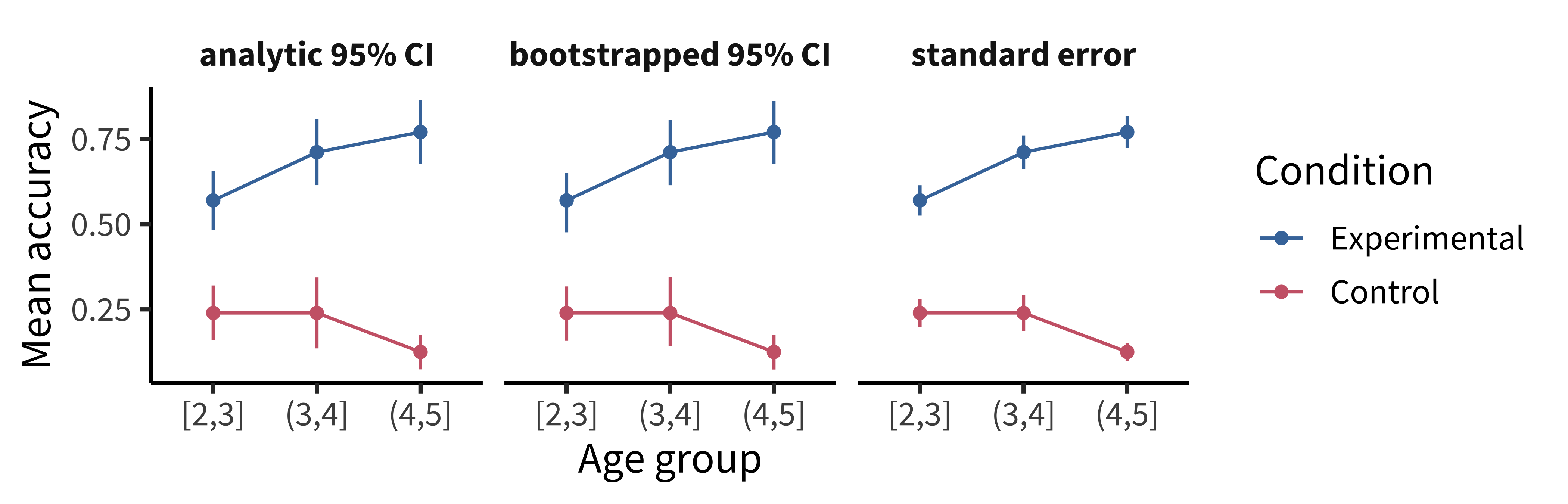
As we can see, the bootstrapped 95% CI looks similar to the analytic 95% CI derived from the standard error, except the upper and lower limits are slightly asymmetric (reflecting outliers in one direction or another). Of course, the bootstrap is not a silver bullet and can be abused in particularly small samples. This is because the bootstrap is fundamentally limited to the sample we run it on. It can be expected to be reasonably accurate if the sample is reasonably representative of the population. But at the end of the day, as they say, “There’s no such thing as a free lunch.” In other words, we cannot magically pull more information out of a small sample without making additional assumptions about the data generating process.
15.1.4 Principle 4: Maximize information, minimize ink
Now that we have the basic graphical elements in place to show our design and data, it might seem like the rest is purely a matter of aesthetic preference, like choosing a pretty color scheme or font. Not so.
There are well-founded principles to make the difference between an effective visualization and a confusing or obfuscating one. Simply put, we should try to use the simplest possible presentation of the maximal amount of information: we should maximize the “data-ink ratio.” To calculate the amount of information shown, Tufte (2001) suggests a measure called the “data density index,” the “numbers plotted per square inch.” The worst offenders have a very low density while also using a lot of excess ink (e.g., figure 15.15 and figure 15.16)
The defaults in modern visualization libraries like ggplot prevent some of the worst offenses but are still often suboptimal. For example: consider whether the visual complexity introduced by the default grey background and grid lines in figure 15.17 is justified, or whether a more minimal theme would be sufficient.
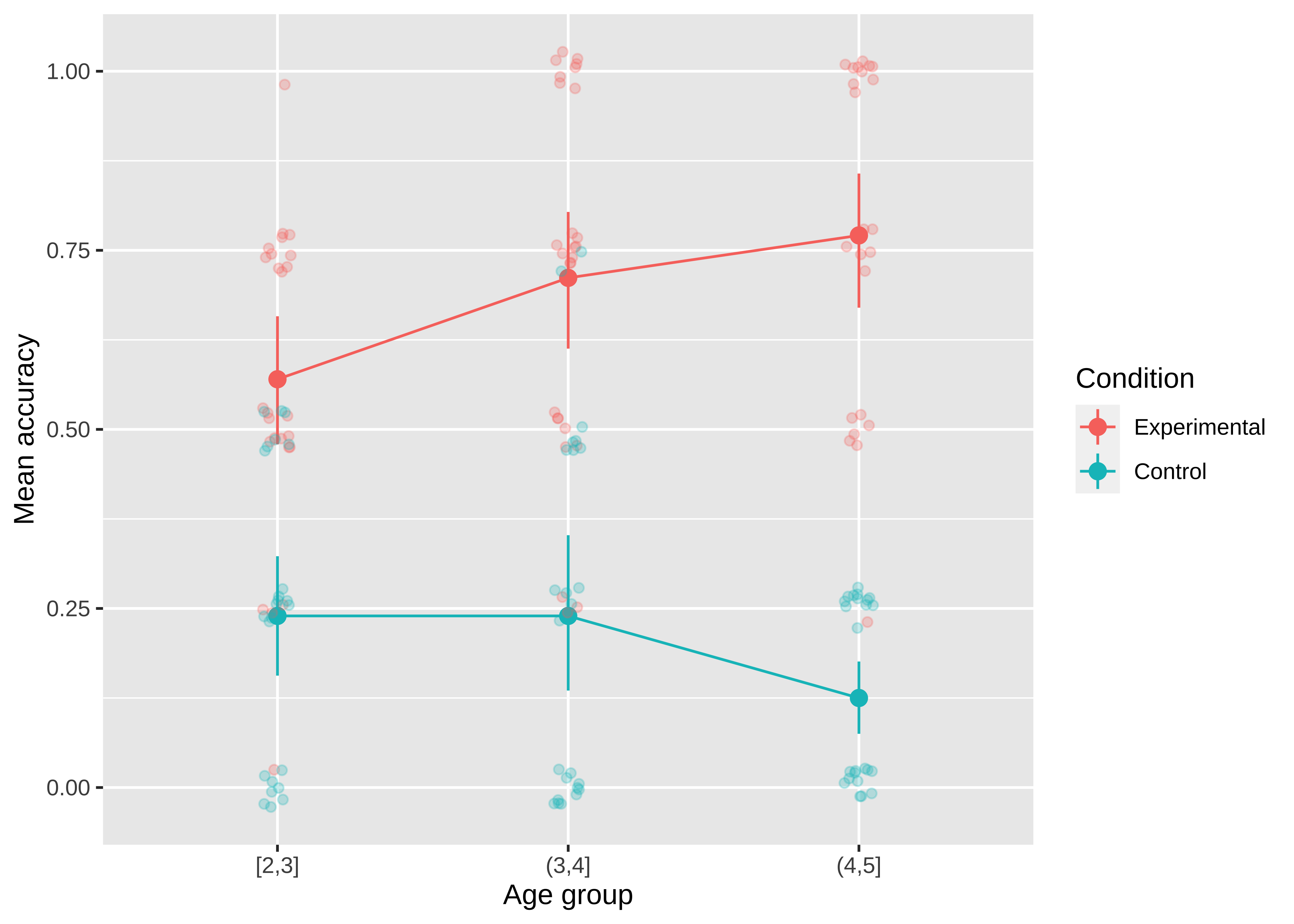
Figure 15.18 shows a slightly more “styled” version of the same plot with labels directly on the plot and a lighter-weight theme.
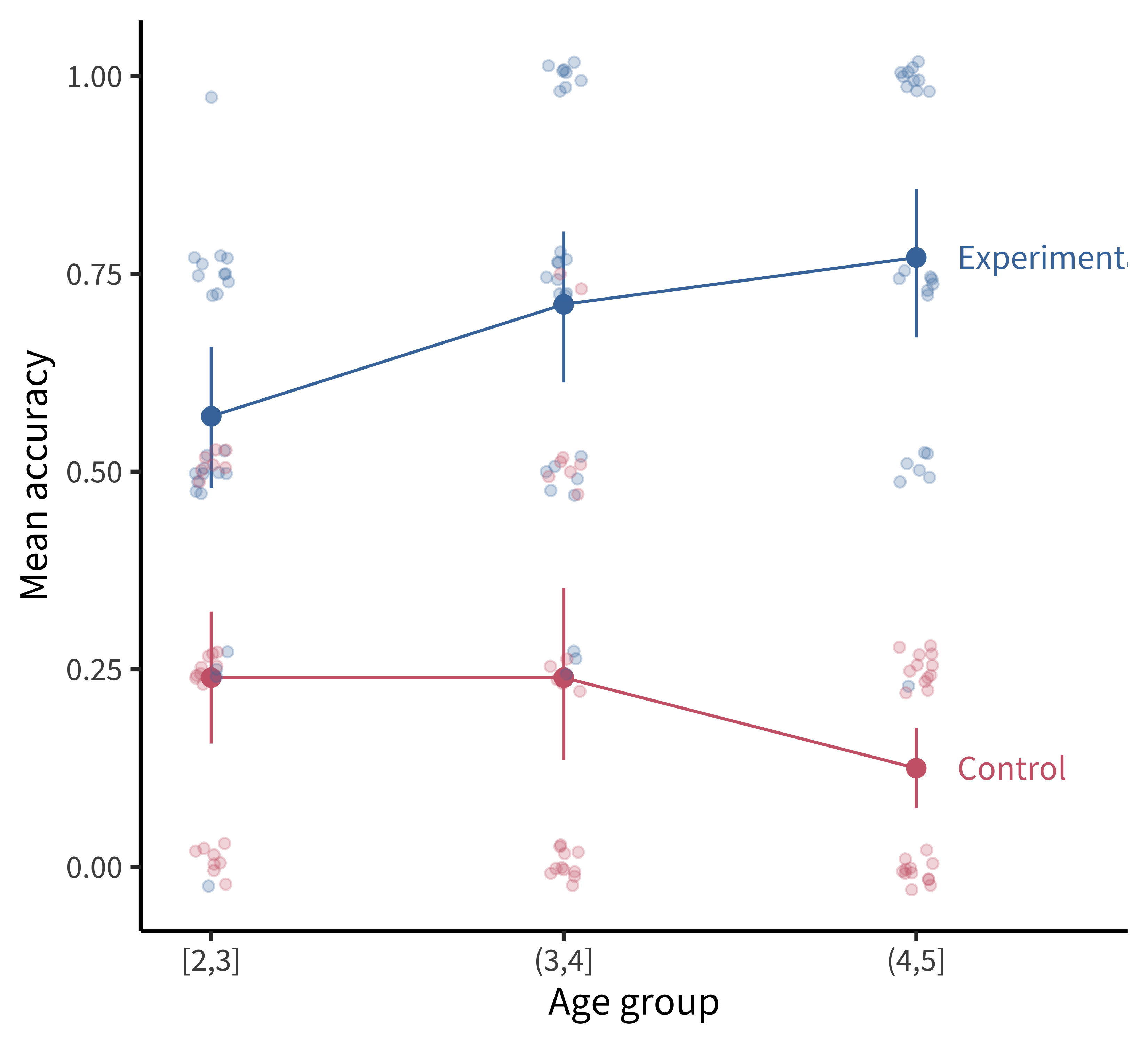
Notecode
To produce the plot in figure 15.18, we’ve added a few styling elements including:
- The nice and minimal custom theme, with a larger font size.
- A more accessible color palette (
scale_colour_ptol()) from theggthemespackage (Arnold 2023). - Direct labels using
geom_dl()from thedirectlabelspackage (Hocking 2023):
geom_dl(aes(label = condition), method = list("last.points", dl.trans(x = x + 0.5)))Here are a few final tips for making good confirmatory visualizations:
Make sure the font size of all text in your figures is legible and no smaller than other text in your paper (e.g., 10 pt). This change may require, for example, making the axis breaks sparser, rotating text, or changing the aspect ratio of the figure.
Another important tool to keep in your visualization arsenal is the facet plot. When your experimental design becomes more complex, consider breaking variables out into a grid of facets instead of packing more and more colors and line-styles onto the same axis. In other words, while higher information density is typically a good thing, you want to aim for the sweet spot before it becomes too dense and confusing. Remember principle 2. When there is too much going on in every square inch, it is difficult to guide your reader’s eye to the comparisons that actually matter, and spreading it out across facets gives you additional control over the salient patterns.
Sometimes these principles come into conflict, and you may need to prioritize legibility over, for example, showing all of the data. For example, suppose there is an outlier orders of magnitude away from the summary statistics. If the axis limits are zoomed out to show that point, then most of the plot will be blank space! It is reasonable to decide that it is not worth compressing the key statistical question of your visualization into the bottom centimeter just to show one point. It may suffice to truncate the axes and note in the caption that a single point was excluded.
Fix the axis labels! A common mistake is to keep the default shorthand you used to name variables in your plotting software instead of more descriptive labels (e.g., “RT” instead of “Reaction Time”). Use consistent terminology for different manipulations and measures in the main text and figures. If anything might be unclear in the figure, explain it in the caption.
Different audiences may require different levels of detail. Sometimes it is better to collapse over secondary variables (even if they are included in your statistical models) to control the density of the figure and draw attention to the key question of interest.
15.2 Exploratory visualization
So far in this chapter we have focused on principles of confirmatory data visualization: how to make production-quality figures that convey the key preregistered analyses without hiding sources of variability or misleading readers about the reliability of the results. Yet, this is only one role that data visualization plays when doing science. An equally important role is called exploratory visualization: the more routine practice of understanding one’s own data by visualizing it. This role is analogous to the sense of exploratory data analyses discussed in chapter 11. We typically do not preregister exploratory visualizations, and when we decide to include them in a paper they are typically in the service of a secondary argument (e.g., checking the robustness of an effect or validating that some assumption is satisfied).
This kind of visualization plays a ubiquitous role in a researcher’s workflow. While confirmatory visualization is primarily audience-driven and concerned with visual communication, exploratory visualization is first and foremost a cognitive tool for the researcher. The first time we load in a new dataset, we start up a new feedback loop—we ask questions and answer them by making visualizations. These visualizations then raise further questions and are often our best tool for debugging our code. Let’s consider some best practices for exploratory visualization.
15.2.1 Examining distributional information
The primary advantage of exploratory visualization—the reason it is uniquely important for data science—is that it gives us access to holistic information about the distribution of the data that cannot be captured in any single summary statistic. The most famous example is known as “Anscombe’s quartet,” a set of four datasets with identical statistics (figure 15.19). They have the same means, the same variances, the same correlation, the same regression line, and the same \(r^2\) value. Yet, when they are plotted, they reveal striking structural differences. The first looks like a noisy linear relationship—the kind of idealized relationship we imagine when we imagine a regression line. But the second is a perfect quadratic arc, the third is a perfectly noiseless line with a single outlier, and the fourth is nearly categorical: every observation except one shares exactly the same x-value.
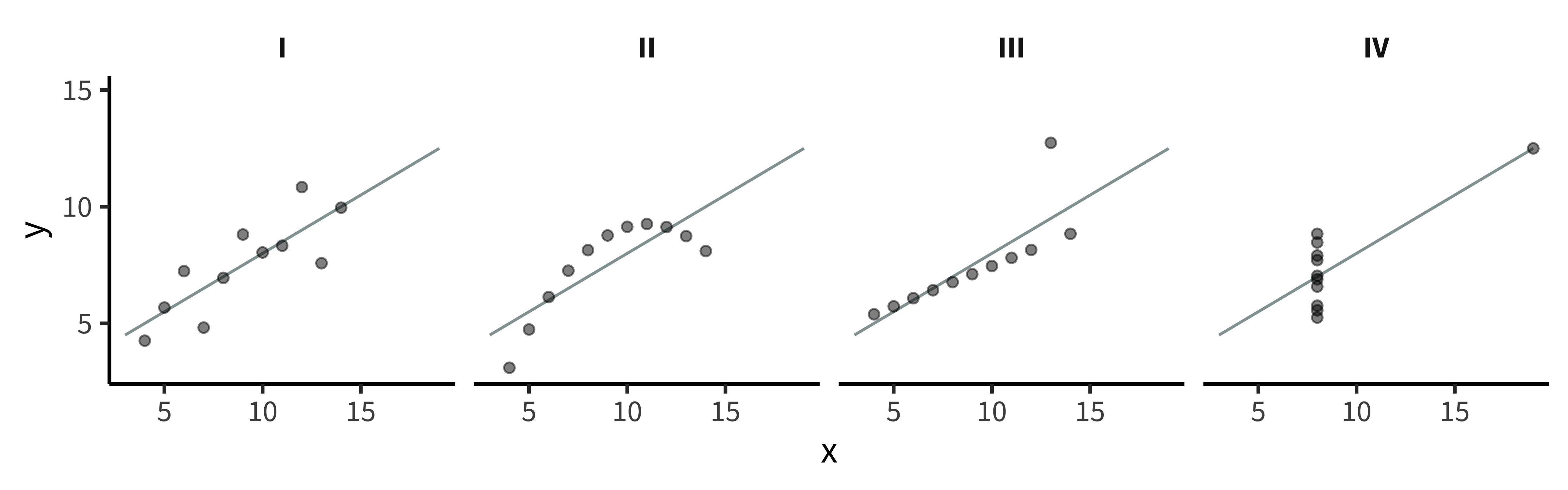
If our analyses are supposed to help us distinguish between different data-generating processes, corresponding to different psychological theories, it is clear that these four datasets would correspond to dramatically different theories even though they share the same statistics. Of course, there are arbitrarily many datasets with the same statistics, and most of these differences don’t matter (this is why they are called “summary” statistics, after all!). Figure 15.20 and table 15.1 show just how bad things can get when we rely on summary statistics. When we operationalize a theory’s predictions in terms of a single statistic (e.g., a difference between groups or a regression coefficient), we can lose track of everything else that may be going on. Good visualizations force us to zoom out and take in the bigger picture.
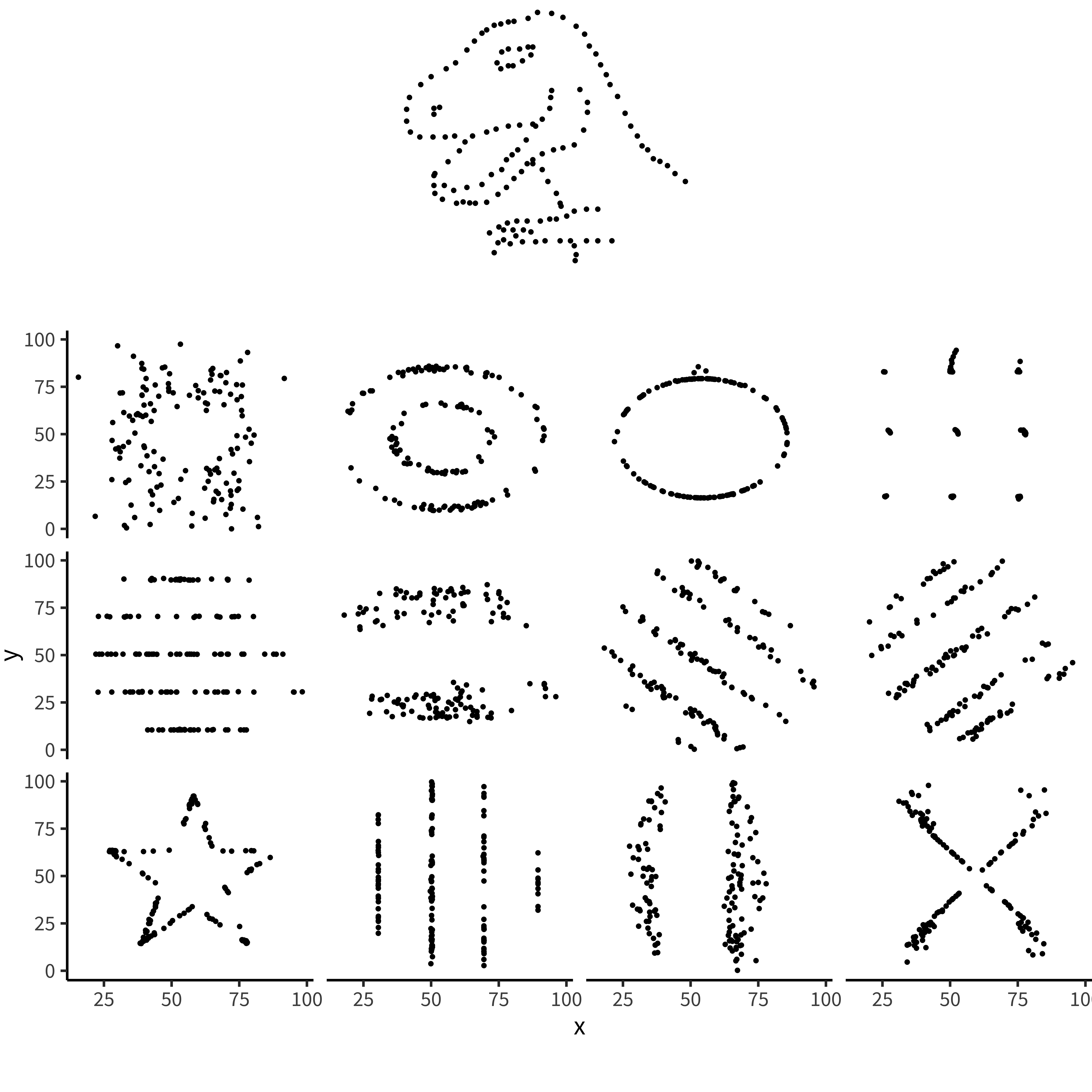
| dataset | mean_x | mean_y | sd_x | sd_y | cor_xy |
|---|---|---|---|---|---|
| away | 54.3 | 47.8 | 16.8 | 26.9 | −0.064 |
| bullseye | 54.3 | 47.8 | 16.8 | 26.9 | −0.069 |
| circle | 54.3 | 47.8 | 16.8 | 26.9 | −0.068 |
| dino | 54.3 | 47.8 | 16.8 | 26.9 | −0.064 |
| dots | 54.3 | 47.8 | 16.8 | 26.9 | −0.060 |
| h_lines | 54.3 | 47.8 | 16.8 | 26.9 | −0.062 |
| high_lines | 54.3 | 47.8 | 16.8 | 26.9 | −0.069 |
| slant_down | 54.3 | 47.8 | 16.8 | 26.9 | −0.069 |
| slant_up | 54.3 | 47.8 | 16.8 | 26.9 | −0.069 |
| star | 54.3 | 47.8 | 16.8 | 26.9 | −0.063 |
| v_lines | 54.3 | 47.8 | 16.8 | 26.9 | −0.069 |
| wide_lines | 54.3 | 47.8 | 16.8 | 26.9 | −0.067 |
| x_shape | 54.3 | 47.8 | 16.8 | 26.9 | −0.066 |
Noteaccident report
[Distributional] gorillas in our midst
Many data scientists don’t bother checking what their data looks like before proceeding to test specific hypotheses. Yanai and Lercher (2020) cleverly designed an artificial dataset for their students to test for such oversight. Each row of the dataset contained an individual’s body mass index (BMI) and the number of steps they walked on a given day. While the spreadsheet looked innocuous, the data was constructed such that simply plotting the raw data revealed a picture of a gorilla. One group of 19 students was given an explicit set of hypotheses to test (e.g., about the relationship between BMI and steps). Fourteen of these students failed to notice a gorilla, suggesting that they evaluated these hypotheses without ever visualizing their data. Another group of 14 students were simply asked what, if anything, they could conclude (without being given explicit hypotheses). More of these students apparently made the visualization, but five of them still failed to notice the gorilla (figure 15.21)!
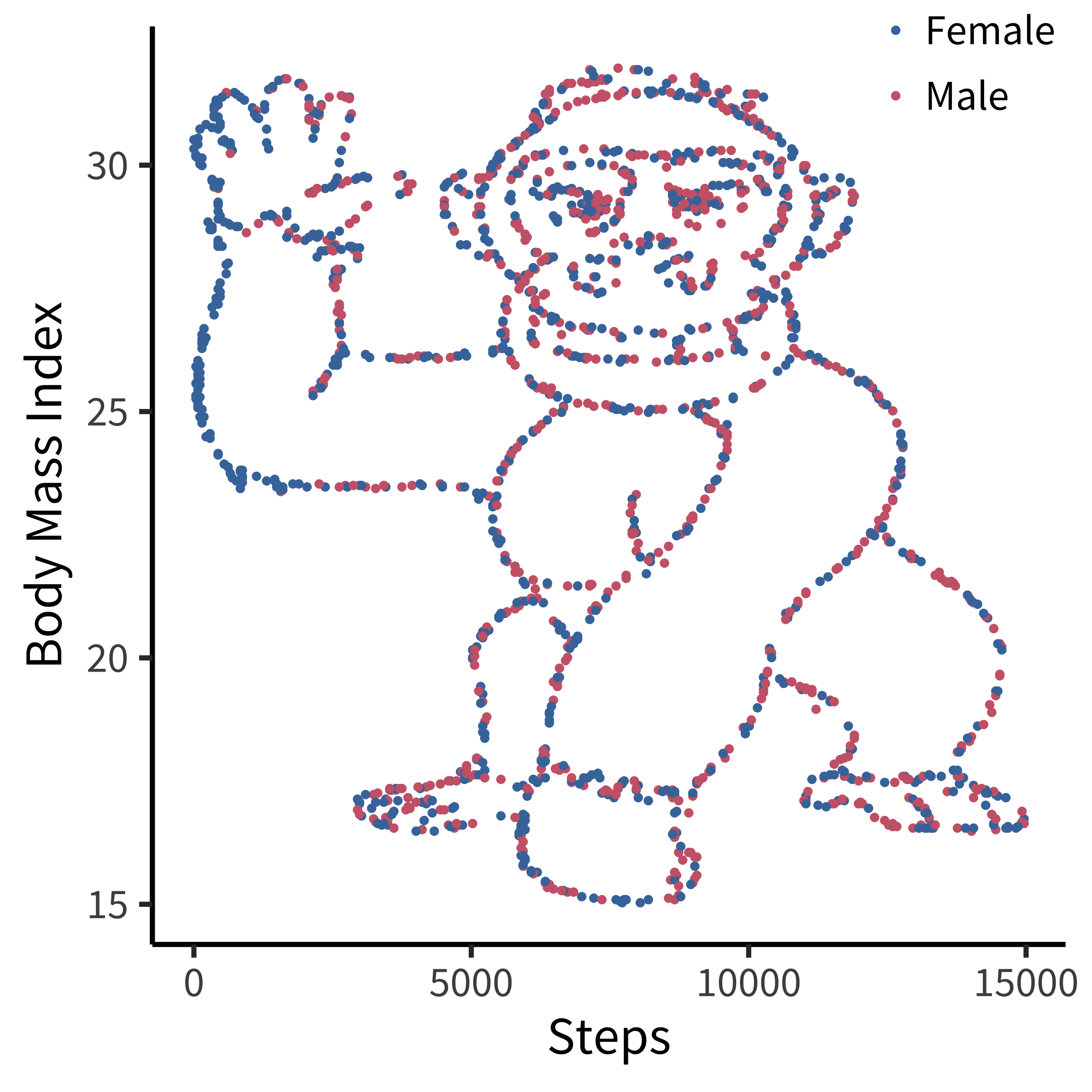
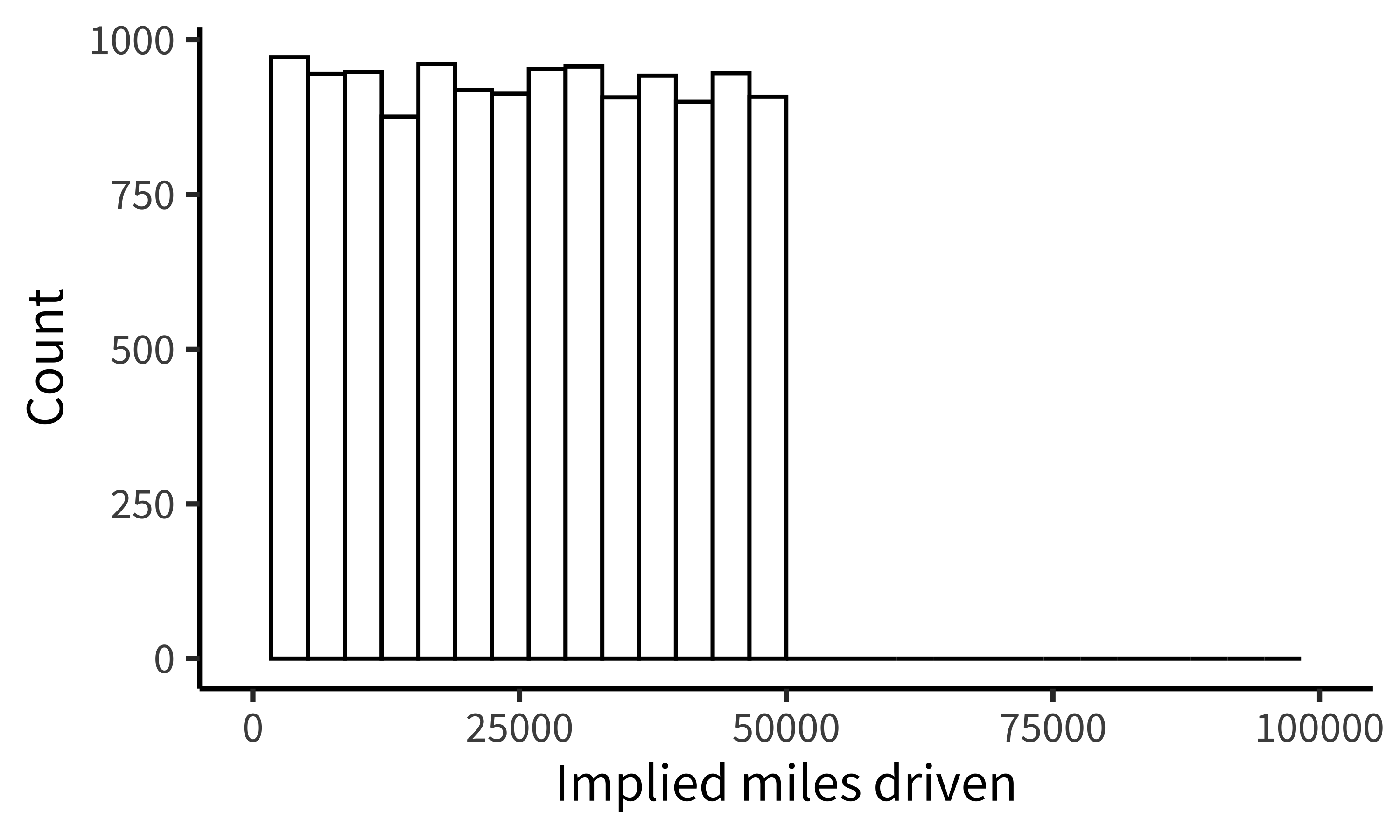
While it may not be surprising that a group of students would take the shortest path to completing their assignment, similar concerns have been raised in much more serious cases concerning how experienced researchers could fail to notice obviously fraudulent data. For example, when the Datacolada bloggers (2021) made a simple histogram of the car mileage data reported in Shu et al. (2012; released publicly by Kristal et al. 2020), they were immediately able to observe that it followed a perfectly uniform distribution, truncated at exactly 50,000 miles (figure 15.22). Given a little thought, this pattern should be extremely puzzling. Over a given period of time, we would typically expect something more bell-shaped: a small number of people will drive very little (e.g., 1,000 miles), a small number of people will drive a lot (e.g., 50,000 miles), and most people will fall between these tails. So it is highly surprising to find exactly the same number of drivers in every mileage bin. While further specialized analyses revealed additional evidence of fraud (e.g., based on patterns of rounding and pairs of duplicated data points), this humble histogram was already enough to set off alarm bells. A recurring regret raised by the coauthors of this paper is that they never thought to make this visualization before reporting their statistical tests.
Our data are always messier than we expect. There might be a bug in our coding scheme, a column might be mislabeled, or it might contain a range of values that we didn’t expect. Maybe our design wasn’t perfectly balanced, or something went wrong with a particular participant’s keyboard presses. Most of the time, it’s not tractable to manually scroll through our raw data looking for such problems. Visualization is our first line of defense for the all-important process of running “data diagnostics.” If there is a weird artifact in our data, it will pop out if we just make the right visualizations.
15.2.2 Data diagnostics
So, which visualizations should we start with? The best practice is to always start by making histograms of the raw data. As an example, let’s consider the rich and interesting dataset shared by Blake et al. (2015) in their article “Ontogeny of Fairness in Seven Societies.” This study examines the emergence of children’s reasoning about fairness—both when it benefits them and when it harms them—across cultures.
In this study, pairs of children played the “inequity game”: they sat across from one another and were given a particular allocation of snacks. On some trials, each participant was allocated the same amount (“equal” trials) and on some trials they were allocated different amounts (“unequal” trials). One participant was chosen to be the “actor” and got to choose whether to accept or reject the allocation: in the case of rejection, neither participant got anything. The critical manipulation was between two forms of inequity. Some pairs were assigned to the “disadvantageous” condition, where the actor was allocated less than their partner on unequal trials (e.g., one vs four). Others were assigned to the “advantageous” condition, where they were allocated more (e.g., four vs one).
The confirmatory design plot for this study would focus on contrasting developmental trajectories for advantageous vs disadvantageous inequality. However, this is a complex, multivariate dataset, including 866 pairs from different age groups and different testing sites across the world which used subtly different protocols. How might we go about the process of exploratory visualization for this dataset?
Notecode
If you want to follow along with this example at home, you can load the data from our repository!
repo <- "https://github.com/langcog/experimentology/raw/main/"
fairness_raw <- read_csv(file.path(repo, "data/viz/ontogeny_of_fairness.csv"))
fairness <- fairness_raw |>
mutate(trial_num = trial |> str_remove("t") |> as.numeric(),
trial_type = eq.uneq |> fct_recode("Equal" = "E", "Unequal" = "U"),
condition = condition |> fct_recode("Advantageous" = "AI",
"Disadvantageous" = "DI"),
age = floor(actor.age.years),
reject = decision == "reject") |>
select(subj_id = actor.id, age, country, condition, trial_num, trial_type, reject) |>
arrange(country, condition, subj_id, trial_num)15.2.3 Plot data collection details
Let’s start by getting a handle on some of the basic sample characteristics. How many participants were in each age bin (figure 15.23)?
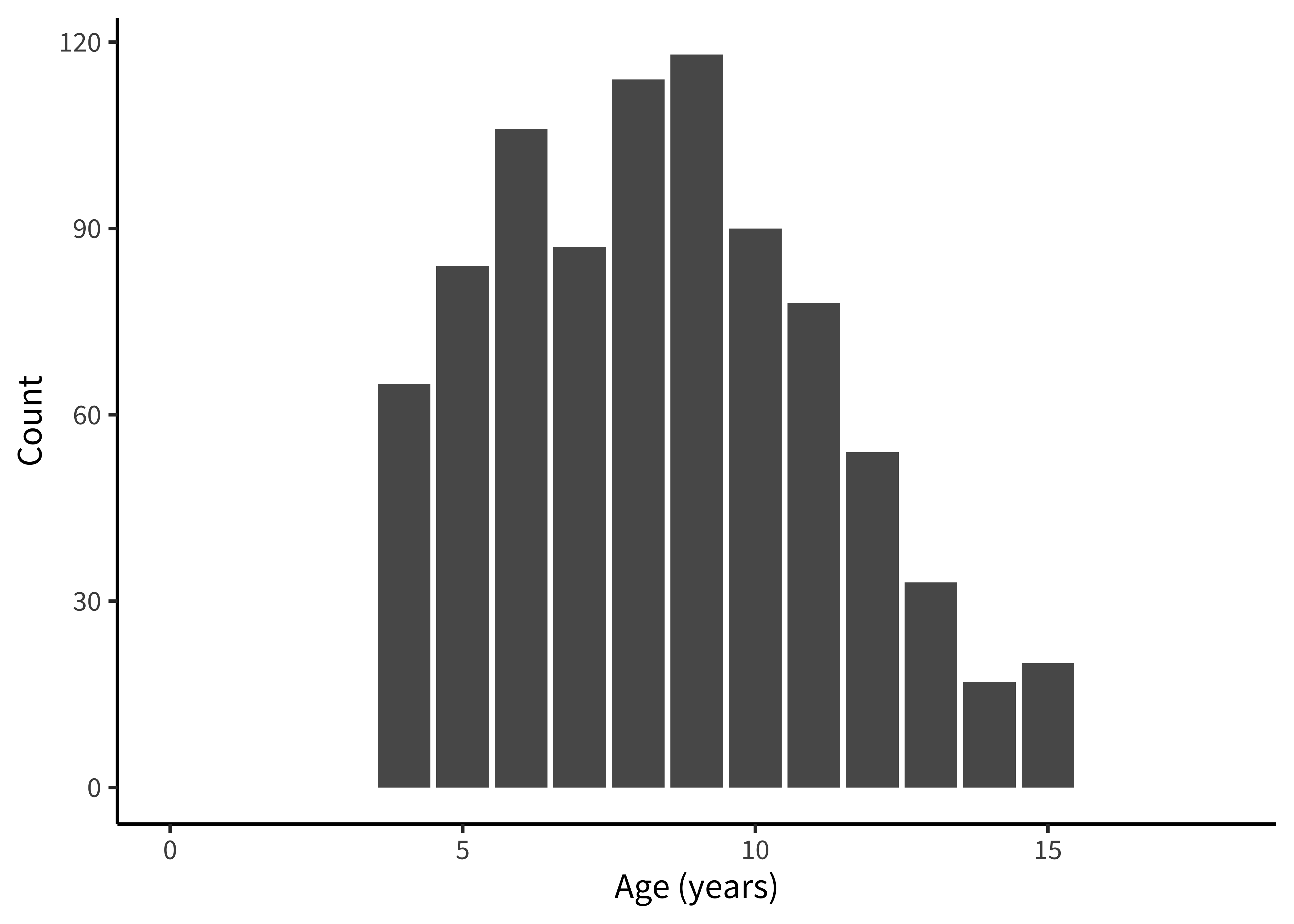
Notecode
Exploratory histograms are often a combination of an aggregation step and a plotting step. In the aggregation step, we make use of the convenience count() function, which gives the number (n) of rows in a particular grouping. Here we count() twice in order to get first one row per participant and then count the number of participants within each age group.
fairness_by_age <- fairness |>
count(age, subj_id) |>
count(age)And then we plot using ggplot():
ggplot(fairness_by_age, aes(x = age, y = n)) +
geom_col() +
xlim(0, 18) +
labs(x = "Age (years)", y = "Count")An alternative (perhaps more elegant) workflow here would be to use a histogram:
fairness_by_age <- fairness |>
count(age, subj_id)
ggplot(fairness_by_age, aes(x = age)) +
geom_histogram(binwidth = 1) +
labs(x = "Age (years)", y = "Count")How many participants were from each country (figure 15.24)?
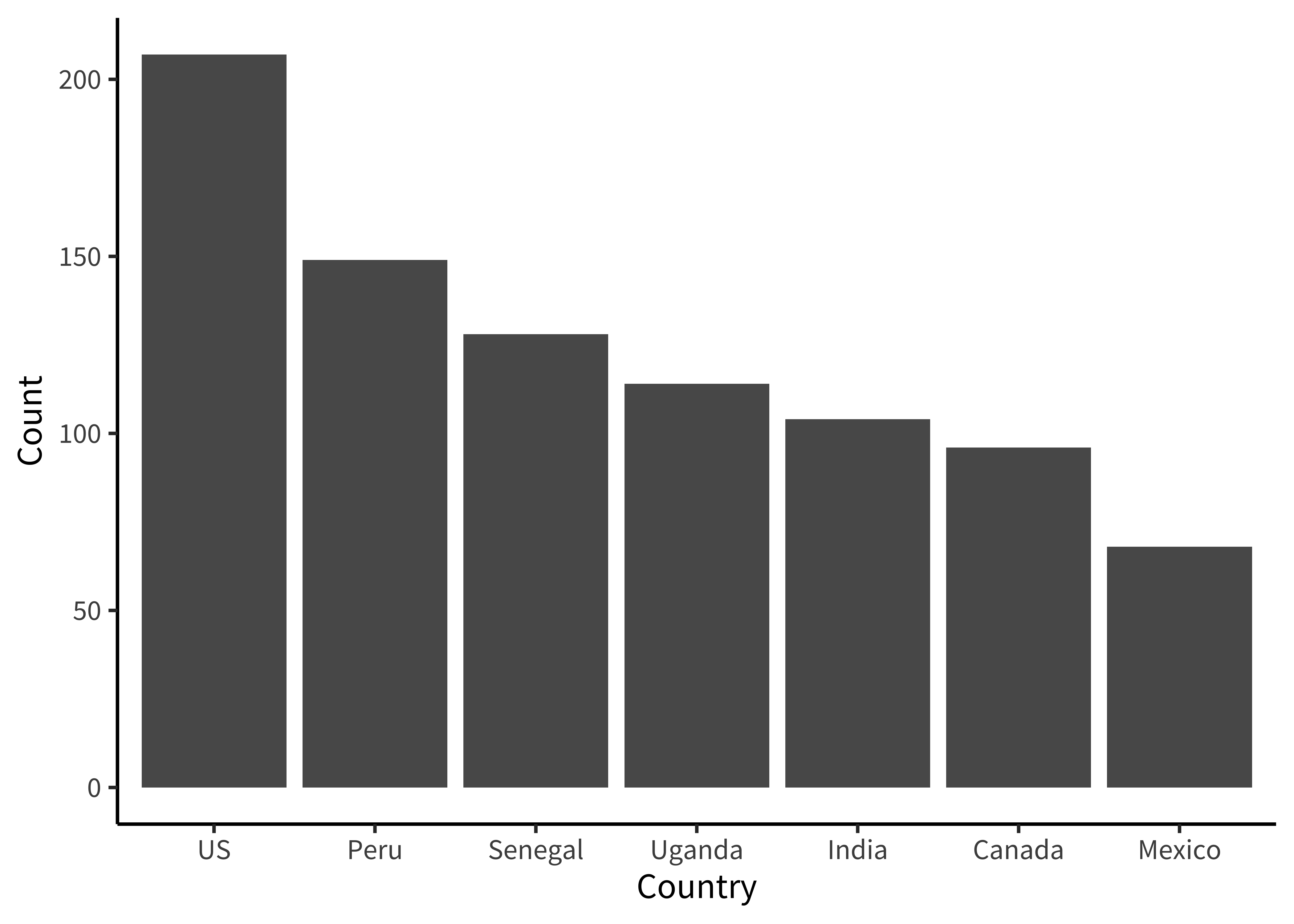
Notecode
Here we are going to make things even terser and use a pipe chain that includes the ggplot() call, just so we are writing only a single call to produce our plot. It’s up to you whether you think this enhances the readability of your code or decreases it. We find that it’s sometimes useful when you don’t plan on keeping the intermediate data frame for any other use than plotting.
fairness |>
count(country, subj_id) |>
count(country) |>
mutate(country = fct_reorder(country, -n)) |>
ggplot(aes(x = country, y = n)) +
geom_col() +
labs(x = "Country", y = "Count")If you use this technique, be careful to use pipe (|> or %>%) between function calls but use + between ggplot layers!
The only other trick to point out here is that we use the fct_reorder() call to order the levels of the country factor in descending order. This function is found in the very useful forcats package (Wickham 2023) of the tidyverse, which contains all sorts of functions for working with factors.
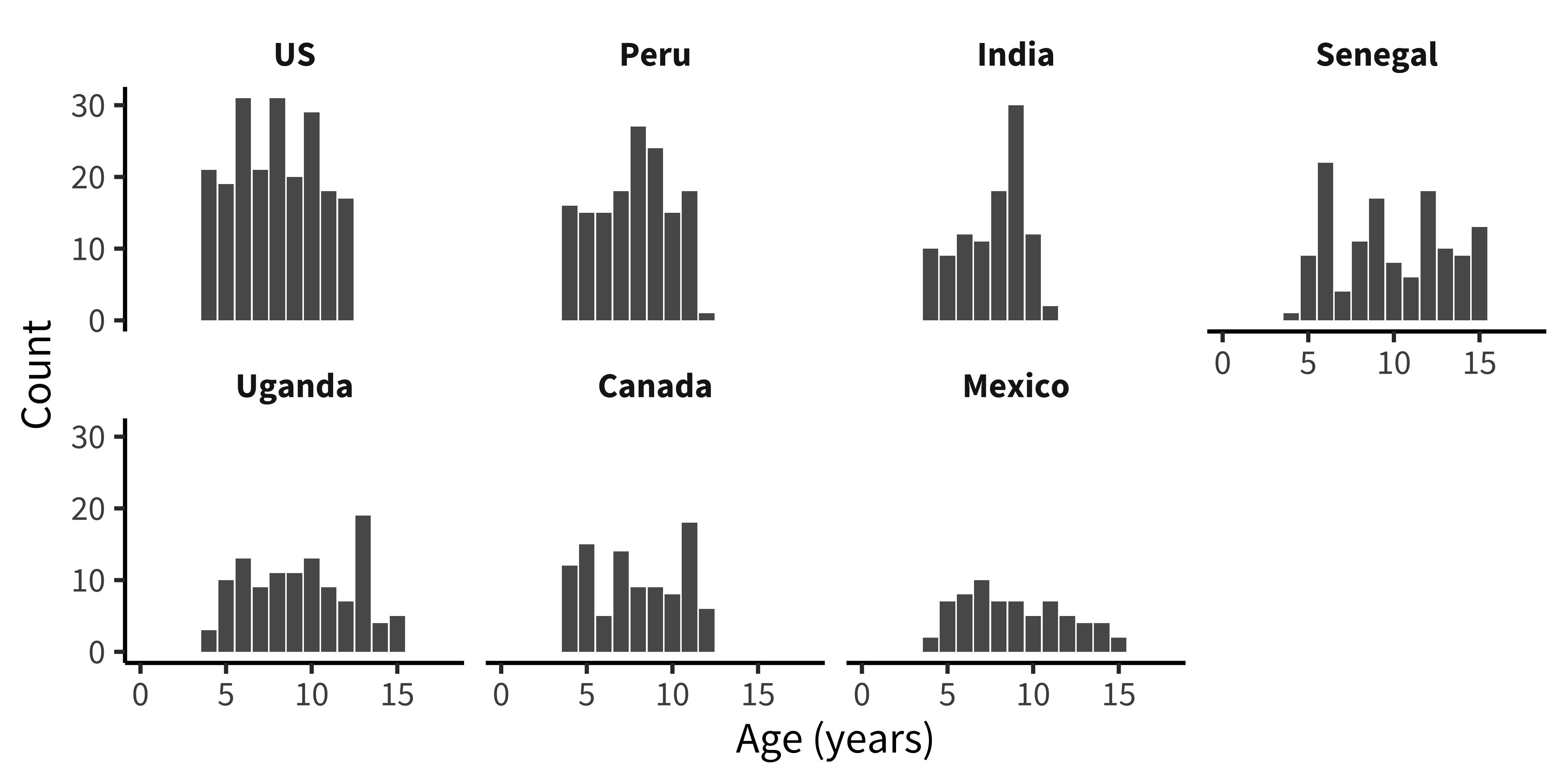
Are ages roughly similar across each country (figure 15.25)?
Notecode
This next plot simply combines the grouping factors of each of the last two plots, and uses facet_wrap() to show a separate histogram by country:
fairness |>
count(country, age, subj_id) |>
count(country, age) |>
mutate(country = fct_reorder(country, -n)) |>
ggplot(aes(x = age, y = n)) +
facet_wrap(vars(country), ncol = 4) +
geom_col() +
xlim(0, 18) +
labs(x = "Age (years)", y = "Count")These exploratory visualizations help us read off some descriptive properties of the sample. For example, we can see that age ranges differ somewhat across sites: the maximum age is 11 in India but 15 in Mexico. We can also see that age groups are fairly imbalanced: in Canada, there are 18 eleven-year-olds but only 5 six-year-olds.
None of these properties are problematic, but seeing them gives us a degree of awareness that could shape our downstream analytic decisions. For example, if we did not appropriately model random effects, our estimates would be dominated by the countries with larger sample sizes. And if we were planning to compare specific groups of six-year-olds (for some reason), this analysis would be underpowered.
15.2.4 Explorating distributions
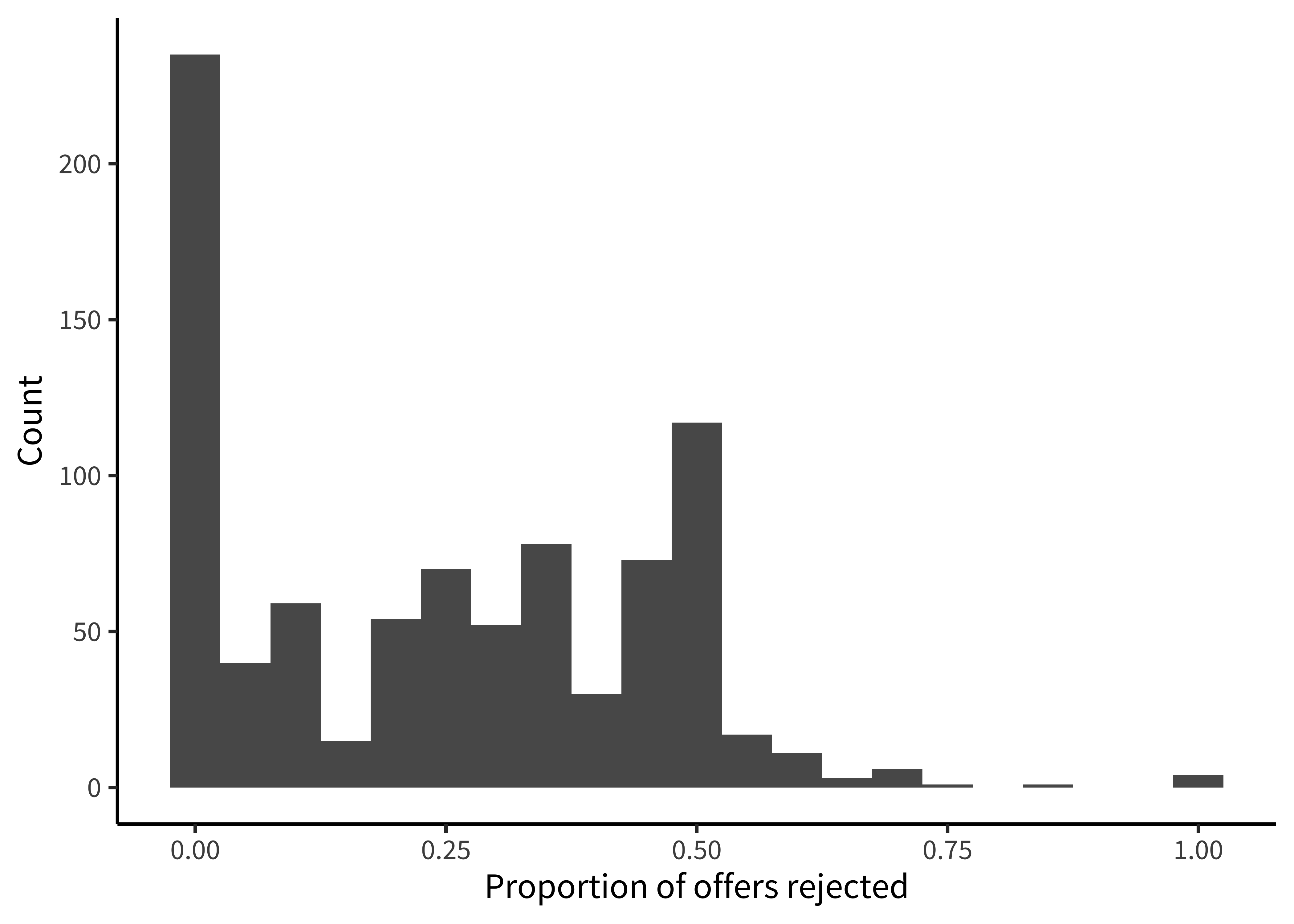
Now that we have a handle on the sample, let’s get a sense of the dependent variable: the participant’s decision to accept or reject the allocation. Before we start taking means, let’s look at how the “rejection rate” variable is distributed. We’ll aggregate at the participant level, and check the frequency of different rejection rates, overall (figure 15.26).
Notecode
Rejection rate is a continuous variable, so we switch to using a histogram in this case, choosing 0.05 as a reasonable bin width to see the distribution.
fairness_by_subj <- fairness |>
filter(!is.na(trial_type)) |>
group_by(subj_id) |>
summarize(mean_reject = mean(reject, na.rm = TRUE))
ggplot(fairness_by_subj, aes(x = mean_reject)) +
geom_histogram(binwidth = .05) +
labs(x = "Proportion of offers rejected", y = "Count")We notice that many participants (27%) never reject in the entire experiment. This kind of “zero-inflated” distribution is not uncommon in psychology, and may warrant special consideration when designing the statistical model. We also notice that there is clumping around certain values. This clumping leads us to check how many trials each participant is completing (figure 15.27).
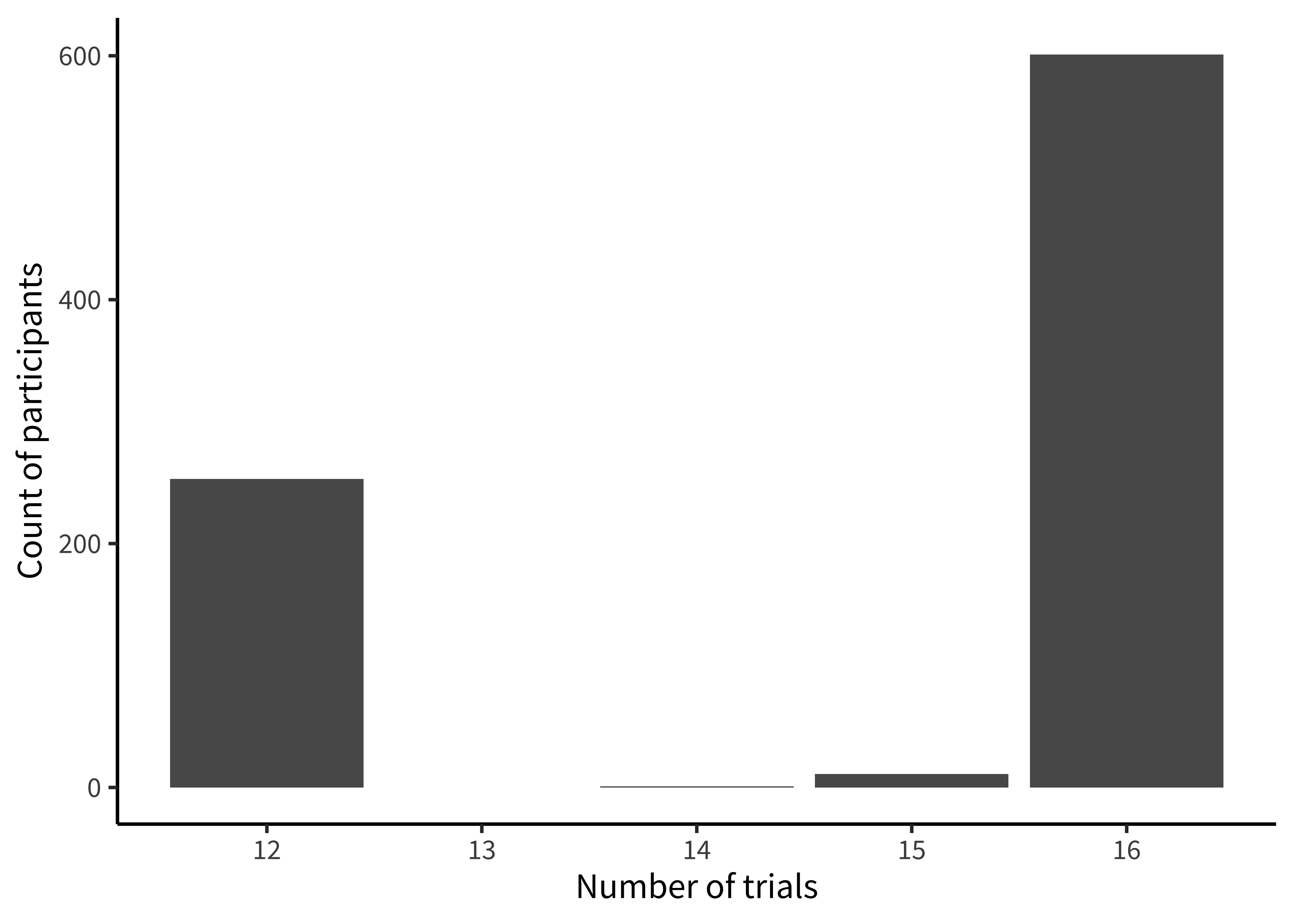
Notecode
This histogram is very similar to the ones above; however, we now use count() twice, first getting the trial counts for each participant and then counting how many times each count occurs overall!
fairness |>
filter(!is.na(trial_type)) |>
count(subj_id) |>
count(n) |>
ggplot(aes(x = n, y = nn)) +
geom_col() +
labs(x = "Number of trials", y = "Count of participants")There’s some variation here: most participants completed 17 trials, but some participants completed 8 trials, and a small number of participants have 14 or 15. Given the logistical complexity of large multi-site studies, it is common to have some changes in experimental protocol across data collection. Indeed, looking at the supplement for the study, we see that while India and Peru had 12 trials, additional trials were added at the other sites. In a design where the number of trials was carefully controlled, seeing unexpected numbers here (like the 14 or 15 trial bins) are clues that something else may be going on in the data. In this case, it was a small number of trials with missing data. More generally, seeing this kind of signal in a visualization of our own data typically leads us to look up the participant IDs in these bins and manually inspect their data to see what might be going on.
15.2.5 Hypothesis-driven exploration
Finally, we can make a few versions of the design plot that are broken out by different variables. Let’s start by just looking at the data from the largest site (figure 15.28).
![4 plots ([dis]advantageous x [un]equal) each showing points and best fit lines for proportion of offers rejected against age.](015-viz_files/figure-html/fig-viz-blake9-1.png)
Figure 15.28 is not a figure we’d put in a paper, but it helps us get a sense of the pattern in the data. There appears to be an age trend that’s specific to the Unequal trials, with rejection rates rising over time (compared to roughly even or decreasing rates in the Equal trials). Meanwhile, rejection rates for the disadvantageous group also seem slightly higher than those in the advantageous group.
Notecode
Here, we are using geom_smooth() to overlay regression trends over the raw data. geom_smooth() takes a number of different options corresponding to different smoothing techniques. Nonparametric smoothing can be a good choice for exploratory visualizations if you have a lot of data and want to make minimal assumptions about the form of the trend.
Here, however, we show the linear regression trend, geom_smooth(method = "lm"), which better corresponds to the predictions of the study and the statistical model being used (see chapter 7). Other regression forms can be specified with the formula argument. For example, we could show quadratic smoothing with geom_smooth(method = "lm", formula = y ~ poly(x, 2)). The form of smoothing you use may differ across exploratory and confirmatory visualizations. In a confirmatory visualization—if you are going to include a smoothing curve—it is typically best to use the one specified by your statistical model, as the slopes will correspond to the inferences being testing.
We begin by making a summary dataset:
fairness_by_age <- fairness |>
filter(!is.na(reject)) |>
group_by(country, trial_type, condition, age, subj_id) |>
summarize(mean_reject_subj = mean(reject, na.rm = TRUE)) |>
group_by(country, trial_type, condition, age) |>
summarize(mean_reject_age = mean(mean_reject_subj, na.rm = TRUE),
n_subj = n()) |>
ungroup()Then we can create the visualization:
fairness_by_age |> filter(country == "US") |>
ggplot(aes(x = age, y = mean_reject_age, color = condition)) +
facet_grid(vars(trial_type), vars(condition)) +
geom_smooth(method = "lm", se = FALSE) +
geom_point(aes(size = n_subj), alpha = .5) +
ylim(c(0, 1)) +
labs(x = "Age (years)", y = "Proportion of offers rejected",
color = "Condition", size = "N subjects") +
theme(legend.position = "bottom", legend.box = "vertical")We often find it convenient to filter the summary dataset in the plotting call, so that we can reuse it again.
Now let’s rebin the data into two-year age groups so that individual point estimates are a bit more reliable, and add in the other countries.5
5 Binning data is a trick that we often use for reducing complexity in a plot when data are noisy. It should be used with care, however, since different binning decisions can sometimes lead to different conclusions. Here we tried several binning intervals and decided that two-year age bins showed the underlying trends pretty well.
![A grid of scatterplots analogous to those in 15.29 but separated by country x [un]equal; color indicates [dis]advantageous.](015-viz_files/figure-html/fig-viz-blake10-1.png)
Figure 15.29 is now looking much closer to a quick-and-dirty version of a “design plot” we might include in a paper. The DV (rejection rate) is on the y-axis, and the primary variable of interest (age) is on the x-axis. Other elements of the design (country and trial type) are mapped to color and facets, respectively.
Notecode
Despite the difference between the plot above and this one, the code to produce them is actually very similar. The only difference is the creation of the binned variable and a slight shift of aesthetic and faceting variables.
fairness_by_age_binned <- fairness |>
filter(!is.na(reject)) |>
mutate(age_binned = floor(age / 2) * 2) |>
group_by(country, trial_type, condition, age_binned, subj_id) |>
summarize(mean_reject_subj = mean(reject, na.rm = TRUE)) |>
group_by(country, trial_type, condition, age_binned) |>
summarize(mean_reject_age = mean(mean_reject_subj, na.rm = TRUE),
n = n()) |>
ungroup()
ggplot(fairness_by_age_binned,
aes(x = age_binned, y = mean_reject_age, color = condition)) +
facet_grid(vars(trial_type), vars(country)) +
geom_smooth(method = "lm", se = FALSE, aes(weight=n)) +
geom_point(alpha = .5, aes(size = n)) +
scale_x_continuous(breaks = seq(4, 12, 4), limits = c(3,13)) +
scale_y_continuous(limits = c(0, 1), breaks = c(0, .5, 1)) +
labs(x = "Age (years)", y = "Proportion of offers rejected",
color = "Condition", size = "N subjects") +
theme(legend.position = "bottom")15.2.6 Visualization as debugging
The point of exploratory visualization is to converge toward a better understanding of what’s going on in your data. As you iterate through different exploratory visualizations, stay vigilant! Think about what you expect to see before making the plot, then ask yourself whether you got what you expected. You can think of this workflow as a form of “visual debugging.” You might notice a data point with an impossible value, such as a proportion greater than one or a reaction time less than zero. Or you might notice weird clusters or striations, which might indicate heterogeneity in data entry (perhaps different coders used slightly different rubrics or rounded in different ways). You might notice that an attribute is missing for some values and trace it back to a bug reading in the data or merging data frames (maybe there was a missing comma in our csv file). If you see anything that looks weird, track it down until you understand why it’s happening. Bugs that are subtle and invisible in other parts of the analysis pipeline will often pop out as red flags in visualizations.
15.3 Chapter summary: Visualization
This chapter has given a short review of the principles of data visualization, especially focusing on the needs of experimental psychology, which are often quite different than those of other fields. We particularly focused on the need to make visualization part of the experimenter’s analytic workflow. Picking up the idea of a “default model” from chapter 7, we discussed a default “design plot” that reflects the key choices made in the experimental design. Within this framework, we then discussed different visualizations of distribution and variability that better align our graphics with the principles of measurement and attention to raw data that we have been advocating throughout.
Notediscussion questions
Choose a recent piece of research that you’ve heard about and try to sketch the “design plot” with pencil and paper. What does and doesn’t work? How does your sketch differ from the visualizations in the paper?
The “design plot” idea that we’ve discussed here can run into problems when an experimental design is too complex to show on a single plot. Imagine you had data from a trial of attention deficit hyperactivity disorder (ADHD) treatment that manipulated both whether a medication was given and whether patients received therapy in a crossed design. The researchers measured two different outcomes: parent report symptom severity and teacher report symptom severity in four different time-points (baseline, three months, six months, and nine months). How could you show the data from such an experiment in a transparent way?
Notereadings
There are many good introductions to data visualization. Here are two social-science focused books whose advice we agree with and that also contain a lot of practical information and helpful R code for the same packages we use here.
Healy, Kieran (2018). Data Visualization: A Practical Introduction. Princeton University Press. Available free online at https://socviz.co.
Wilke, Claus O. (2019). Fundamentals of Data Visualization: A Primer on Making Informative and Compelling Figures. O’Reilly Media. Available free online at https://clauswilke.com/dataviz.
For a more classical treatment, see:
Allen, Micah, Davide Poggiali, Kirstie Whitaker, Tom Rhys Marshall, and Rogier A Kievit. 2019. “Raincloud Plots: A Multi-Platform Tool for Robust Data Visualization.” Wellcome Open Research 4.
Anscombe, Francis J. 1973. “Graphs in Statistical Analysis.” The American Statistician 27 (1): 17–21.
Arnold, Jeffrey B. 2023. ggthemes: Extra Themes, Scales and Geoms for ggplot2. https://CRAN.R-project.org/package=ggthemes.
Blake, P R, K McAuliffe, J Corbit, T C Callaghan, O Barry, A Bowie, L Kleutsch, et al. 2015. “The Ontogeny of Fairness in Seven Societies.” Nature 528 (7581): 258–61.
Börner, Katy, Andreas Bueckle, and Michael Ginda. 2019. “Data Visualization Literacy: Definitions, Conceptual Frameworks, Exercises, and Assessments.” Proceedings of the National Academy of Sciences 116 (6): 1857–64.
Braginsky, Mika, and Daniel Yurovsky. 2018. tidyboot: Tidyverse-Compatible Bootstrapping. https://CRAN.R-project.org/package=tidyboot.
Brody, Howard, Michael Russell Rip, Peter Vinten-Johansen, Nigel Paneth, and Stephen Rachman. 2000. “Map-Making and Myth-Making in Broad Street: The London Cholera Epidemic, 1854.” The Lancet 356 (9223): 64–68.
Cleveland, William S, and Robert McGill. 1984. “Graphical Perception: Theory, Experimentation, and Application to the Development of Graphical Methods.” Journal of the American Statistical Association 79 (387): 531–54.
Coppock, Alexander. 2019. “Visualize as You Randomize: Design-Based Statistical Graphs for Randomized Experiments.” In Advances in Experimental Political Science, edited by James N. Druckman and Donald P. Green, 320–36. Cambridge University Press.
Datacolada. 2021. “Evidence of Fraud in an Influential Field Experiment about Dishonesty.” https://datacolada.org/98.
Friendly, Michael, and Howard Wainer. 2021. A History of Data Visualization and Graphic Communication. Harvard University Press.
Gelman, Andrew, and Antony Unwin. 2013. “Infovis and Statistical Graphics: Different Goals, Different Looks.” Journal of Computational and Graphical Statistics 22 (1): 2–28.
Halliday, Stephen. 2001. “Death and Miasma in Victorian London: An Obstinate Belief.” British Medical Journal 323 (7327): 1469–71.
Healy, Kieran. 2018. Data Visualization: A Practical Introduction. Princeton University Press.
Henry, Lionel, Hadley Wickham, and Winston Chang. 2022. ggstance: Horizontal ggplot2 Components. https://CRAN.R-project.org/package=ggstance.
Hocking, Toby Dylan. 2023. directlabels: Direct Labels for Multicolor Plots. https://CRAN.R-project.org/package=directlabels.
Kristal, Ariella S, Ashley V Whillans, Max H Bazerman, Francesca Gino, Lisa L Shu, Nina Mazar, and Dan Ariely. 2020. “Signing at the Beginning Versus at the End Does Not Decrease Dishonesty.” Proceedings of the National Academy of Sciences 117 (13): 7103–7.
Mackinlay, Jock. 1986. “Automating the Design of Graphical Presentations of Relational Information.” ACM Transactions on Graphics 5 (2): 110–41.
Matejka, Justin, and George Fitzmaurice. 2017. “Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing.” In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, 1290–94.
Murray, Lori L, and John G Wilson. 2021. “Generating Data Sets for Teaching the Importance of Regression Analysis.” Decision Sciences Journal of Innovative Education 19 (2): 157–66.
Roeder, Kathryn. 1994. “DNA Fingerprinting: A Review of the Controversy.” Statistical Science 9 (2): 222–47.
Shu, Lisa L, Nina Mazar, Francesca Gino, Dan Ariely, and Max H Bazerman. 2012. “Signing at the Beginning Makes Ethics Salient and Decreases Dishonest Self-Reports in Comparison to Signing at the End.” Proceedings of the National Academy of Sciences 109 (38): 15197–200.
Snow, John. 1854. “Dr. Snow’s Report.” In Report on the Cholera Outbreak in the Parish of St. James, Westminster, During the Autumn of 1854. John Churchill. https://johnsnow.matrix.msu.edu/work.php?id=15-78-55.
———. 1855. On the Mode of Communication of Cholera. John Churchill.
Stiller, Alex J, Noah D Goodman, and Michael C Frank. 2015. “Ad-Hoc Implicature in Preschool Children.” Language Learning and Development 11 (2): 176–90.
Tufte, Edward R. 2001. The Visual Display of Quantitative Information. 2nd ed. Graphics Press.
Tukey, John W. 1977. Exploratory Data Analysis. Pearson.
Wainer, Howard. 1984. “How to Display Data Badly.” The American Statistician 38 (2): 137–47.
Wickham, Hadley. 2023. forcats: Tools for Working with Categorical Variables (Factors). https://CRAN.R-project.org/package=forcats.
Wilke, Claus O. 2019. Fundamentals of Data Visualization: A Primer on Making Informative and Compelling Figures. O’Reilly Media.
Yanai, I, and M Lercher. 2020. “A Hypothesis Is a Liability.” Genome Biology 21, 231 (2020). https://doi.org/10.1186/s13059-020-02133-w.
Zacks, Jeffrey M, and Steven L Franconeri. 2020. “Designing Graphs for Decision-Makers.” Policy Insights from the Behavioral and Brain Sciences 7 (1): 52–63.