tea_data <- make_tea_data(n_total = 18)6 Inference
Notelearning goals
- Discuss the purpose of statistical inference
- Define \(p\)-values and Bayes Factors
- Consider common fallacies about inference (especially for \(p\)-values)
- Reason about sampling variability
- Define and reason about confidence intervals
We’ve been arguing that experiments are about measuring effects. The effects we are interested in are causal effects for a group of people, but that group is almost always bigger than the participants in an experiment. Statistical inference is the process of going beyond the specific characteristics of the sample that you measured to make generalizations about the broader population.
chapter 5 already showed us how to make one simple inference: estimating population parameters using both frequentist and Bayesian techniques. Estimating population parameters is an important first step. But often we want to make more sophisticated inferences so that we can answer questions such as:
- How likely is it that this pattern of measurements was produced by chance variation?
- Do these data provide more support for one hypothesis or another?
- How precise is our estimate of an effect?
- What portion of the variation in the data is due to a particular manipulation (as opposed to variation between participants, stimulus items, or other manipulations)?
Question (1) is associated with one particular type of statistical inference method—null hypothesis significance testing (NHST) in the frequentist statistical tradition. NHST has become synonymous with data analysis, such that in the vast majority of research papers (and research methods courses), all of the reported analyses are tests of this type. Yet, this equivalence is quite problematic.
The move to “go test for significance” before visualizing your data and trying to understand sources of variation (participants, items, manipulations, and other sources) is one of the most unhelpful strategies for an experimenter. Whether \(p < 0.05\) or not, a test of this sort gives you literally one bit of information about your data.1 Considering effect sizes and their variation more holistically, including using the kinds of visualizations we advocate in chapter 15, gives you a much richer sense of what happened in your experiment!
1 In the information theoretic sense, as well as the common sense!
In this chapter, we will describe NHST, the conventional method that many students still learn (and many scientists still use) as their primary method for engaging with data. All practicing experimentalists need to understand NHST, both to read the literature and also to apply this method in appropriate situations. For example, NHST may be a reasonable tool for testing whether an intervention leads to a difference between a treatment condition and an appropriate control. But we will also try to contextualize NHST as a very special case of a broader set of statistical inference strategies. Further, we will continue to flesh out our account of how some of the pathologies of NHST have been a driver of the replication crisis.
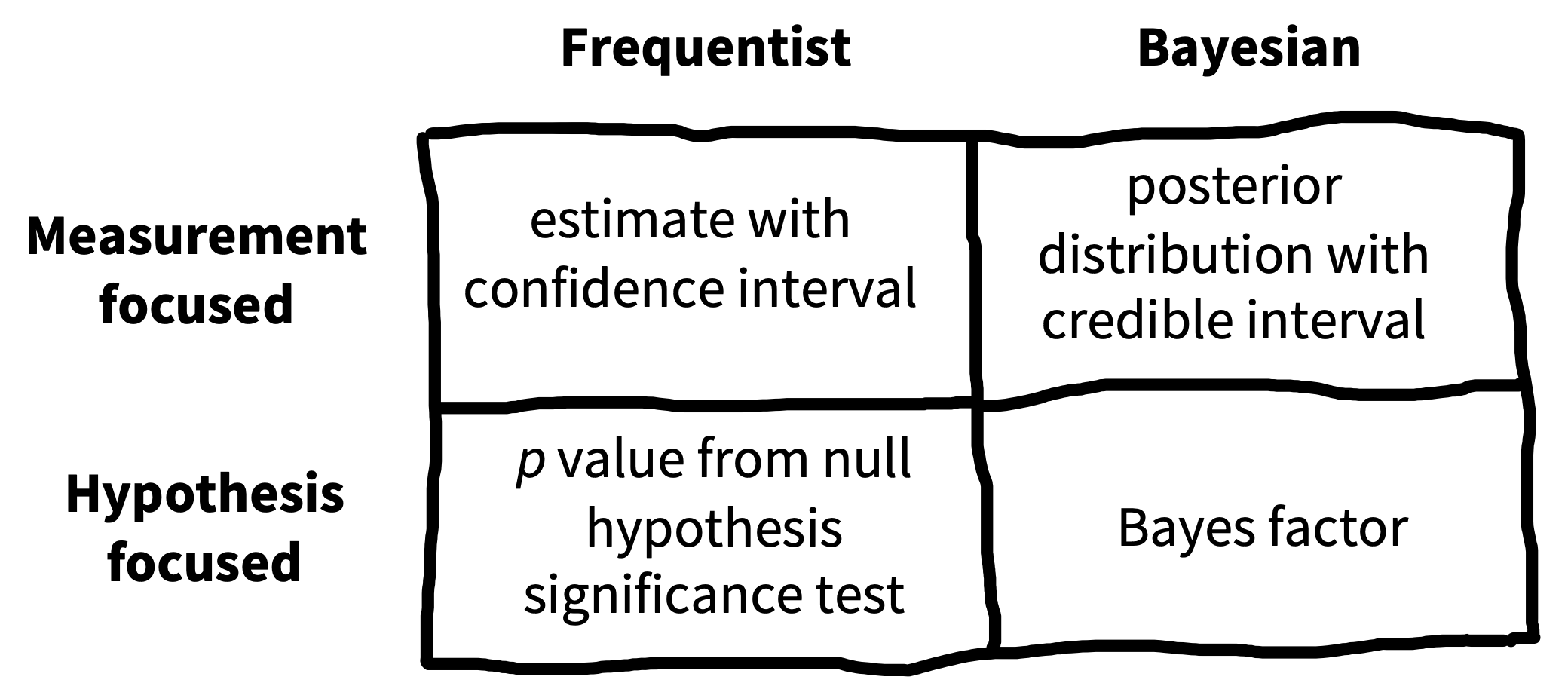
If NHST approaches have so many issues, what should replace them? Figure 6.1 shows one way of organizing different inferential approaches. There has been a recent move toward the use of Bayes Factors to quantify the evidence in support of different candidate hypotheses. Bayes Factors can help answer questions like (2). We introduce these tools and we believe that they have broader applicability than the NHST framework and should be known by students. On the other hand, Bayes Factors are not a panacea. They have many of the same problems as NHST when they are applied dichotomously.
Instead of dichotomous frequentist or Bayesian hypothesis testing, we follow our thematic emphasis on measurement precision and advocate for a measurement strategy, which is more suited toward questions (3) and (4) (Cumming 2014; Kruschke and Liddell 2018b). The goal of these strategies is to yield an accurate and precise estimate of the relationships underlying observed variation in the data.
This isn’t a statistics book, and we won’t attempt to teach the full array of important statistical concepts that will allow students to build good models of a broad array of datasets (Sorry!).2 But we do want you to be able to reason about inference and modeling. In this chapter, we’ll start by making some inferences about our tea-tasting example from the last chapter, using this example to build up intuitions about hypothesis testing and inference. Then, in chapter 7, we’ll start to look at more sophisticated models and how they can be fit to real datasets.
2 If you’re interested in going deeper, here are two books that have been really influential for us. The first is Gelman and Hill (2006) and its successor Gelman, Hill, and Vehtari (2020), which teach regression and multi-level modeling from the perspective of data description. The second is McElreath (2018), a course on building Bayesian models of the causal structure of your data. Honestly, neither is an easy book to sit down and read (unless you are the kind of person who reads statistics books on the subway for fun), but both really reward detailed study. We encourage you to get together a reading group and go through the exercises in one of these together. It’ll be well worthwhile in its impact on your statistical and scientific thinking.
6.1 Sampling variation
In chapter 5, we introduced Fisher’s tea-tasting experiment and discussed how to estimate means and differences in means from our observed data. These so-called point estimates represent our best guesses about the population parameters given the data—and possibly also given our prior beliefs. We can also report how much statistical uncertainty is involved in these point estimates.3 Quantifying and reasoning about this uncertainty is an important goal: in our original study we only had nine participants in each group, which will only provide a low-precision (i.e., highly uncertain) estimate of the population. By contrast, if we repeated the experiment with 200 participants in each group, the data would be far less noisy, and we would have much less uncertainty, even if the point estimates happened to be identical.
3 As in the previous chapter, we’re only capturing statistical uncertainty. A holistic view of a particular estimate’s credibility also include everything else you know about the study design.
6.1.1 Standard errors
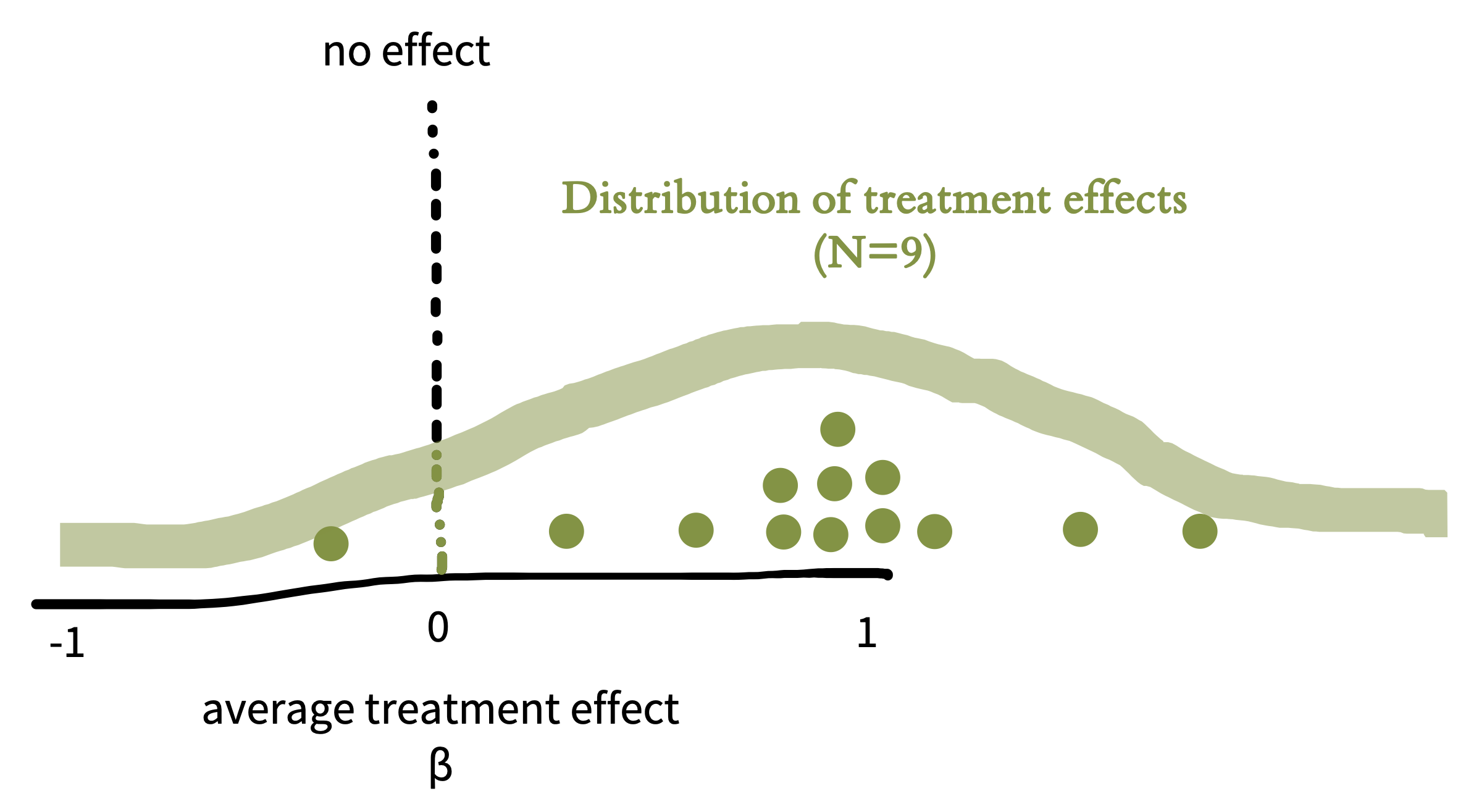
To characterize the uncertainty in an estimate, it helps to picture its sampling distribution, which is the distribution of the estimate across different, hypothetical, samples. That is, let’s imagine that we conducted the tea experiment not just once but dozens, hundreds, or even thousands of times. This idea is often called repeated sampling as a shorthand. For each hypothetical sample, we use similar recruitment methods to recruit a new sample of participants, and we compute \(\widehat{\beta}\) for that sample. Would we get exactly the same answer each time? No, simply because the samples will have some random variability (noise). If we plotted these estimates, \(\widehat{\beta}\), we would get the sampling distribution in figure 6.2.
Notecode
In this chapter and the subsequent statistics and visualization chapters of the book, we’ll try to facilitate understanding and illustrate how to use these concepts in practice by giving the R code we use in constructing our examples in these code boxes. We’ll assume that you have some knowledge of base R and the Tidyverse—to get started with these, go ahead and take a look at appendix D if you haven’t already. Although our figures are often drawn by hand, even the hand-drawn ones are based on actual simulation results!
Since we’re going to be working with lots of data from the tea tasting example, we wrote a function called make_tea_data() that creates a tibble with some (made-up) data from our modern tea-tasting experiment. You can find the function on GitHub (https://github.com/langcog/experimentology/blob/main/helper/tea_helper.qmd) if you want to follow along.
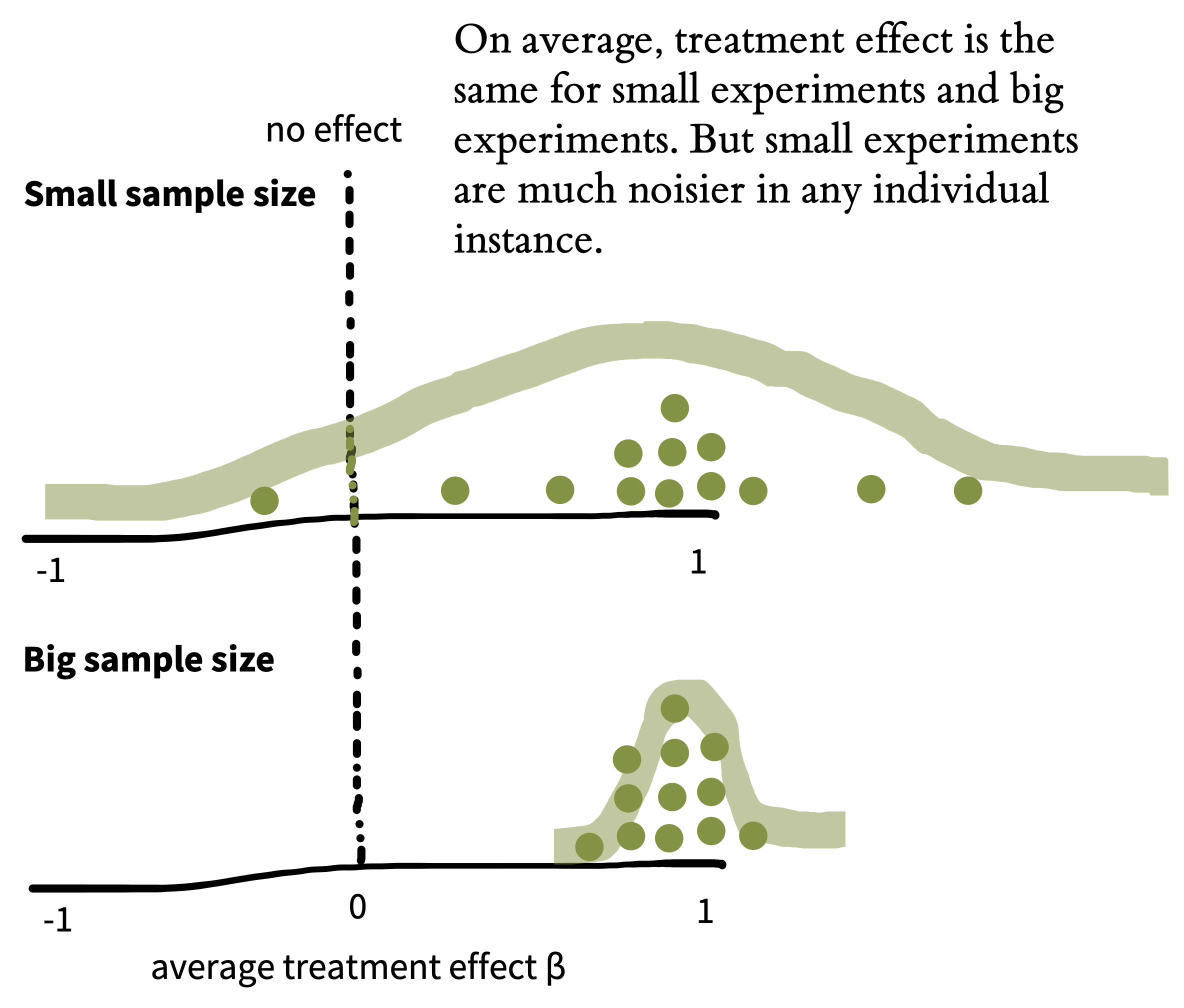
Now imagine we also did thousands of repetitions of the experiment with \(n = 200\) per group instead of \(n = 9\) per group. Figure 6.3 shows what the sampling distribution might look like in that case. Notice how much narrower the sampling distribution becomes when we increase the sample size, showing our decreased uncertainty. More formally, the standard deviation of the sampling distribution itself, called the standard error, decreases as the sample size increases.
The sampling distribution is not the same thing as the distribution of tea ratings in a single sample. Instead, it’s a distribution of estimates across samples of a given size. In essence, it tells us what the mean of a new experiment might be, if we ran it with a particular sample size.
Notecode
To do simulations where we repeat the tea-tasting experiment over and over again, we’re using a special tidyverse function from the purrr library: map(). map() is an extremely powerful function that allows us to run another function (in this case, the make_tea_data() function that we introduced last chapter) many times with different inputs. Here we create a tibble made up of a set of 1,000 runs of the make_tea_data() function.
samps <- tibble(sim = 1:1000) |>
mutate(data = map(sim, \(i) make_tea_data(n_total = 18))) |>
unnest(cols = data)Next, we just use the group_by() and summarize() workflow from appendix D to get the estimated treatment effect for each of these simulations.
tea_summary <- samps |>
group_by(sim, condition) |>
summarize(mean_rating = mean(rating)) |>
group_by(sim) |>
summarize(delta = mean_rating[condition == "milk first"] -
mean_rating[condition == "tea first"])This tibble gives us what we would need to plot the sampling distributions above in figure 6.2 and figure 6.3.
6.1.2 The central limit theorem
We talked in the last chapter about the normal distribution, a convenient and ubiquitous tool for quantifying the distribution of measurements. A shocking thing about sampling distributions for many kinds of estimates—and for all maximum likelihood estimates—is that they become normally distributed as the sample size gets larger and larger. This result holds even for estimates that are not even remotely normally distributed in small samples!
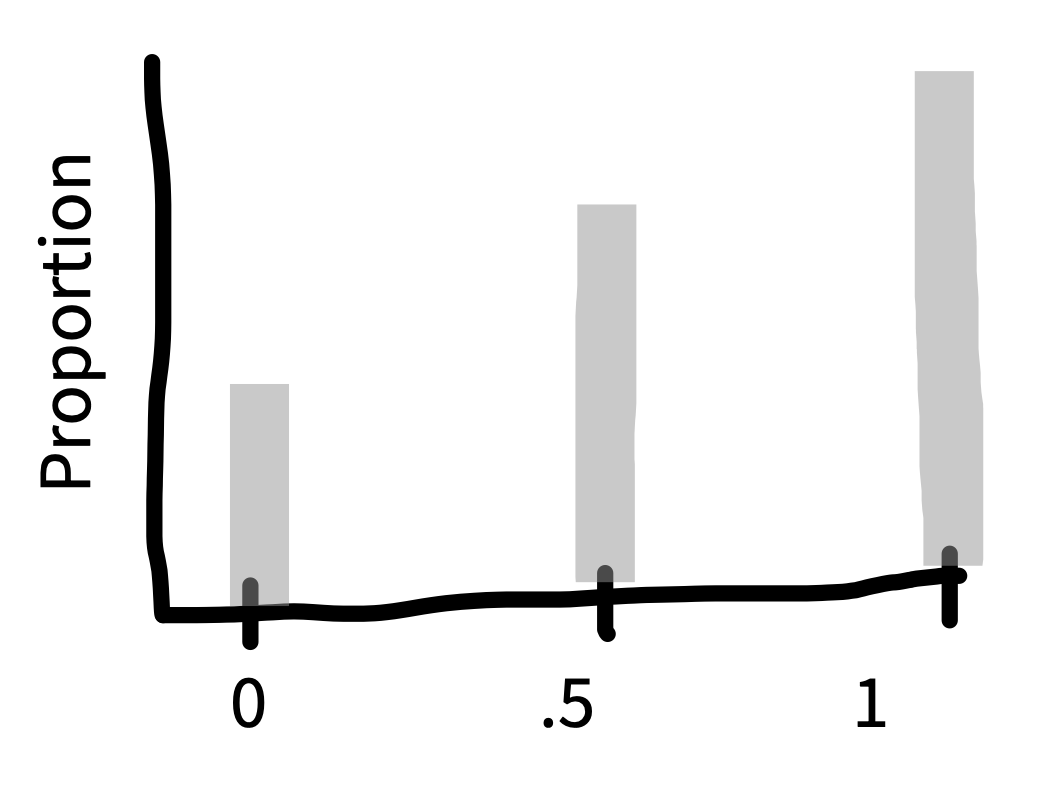
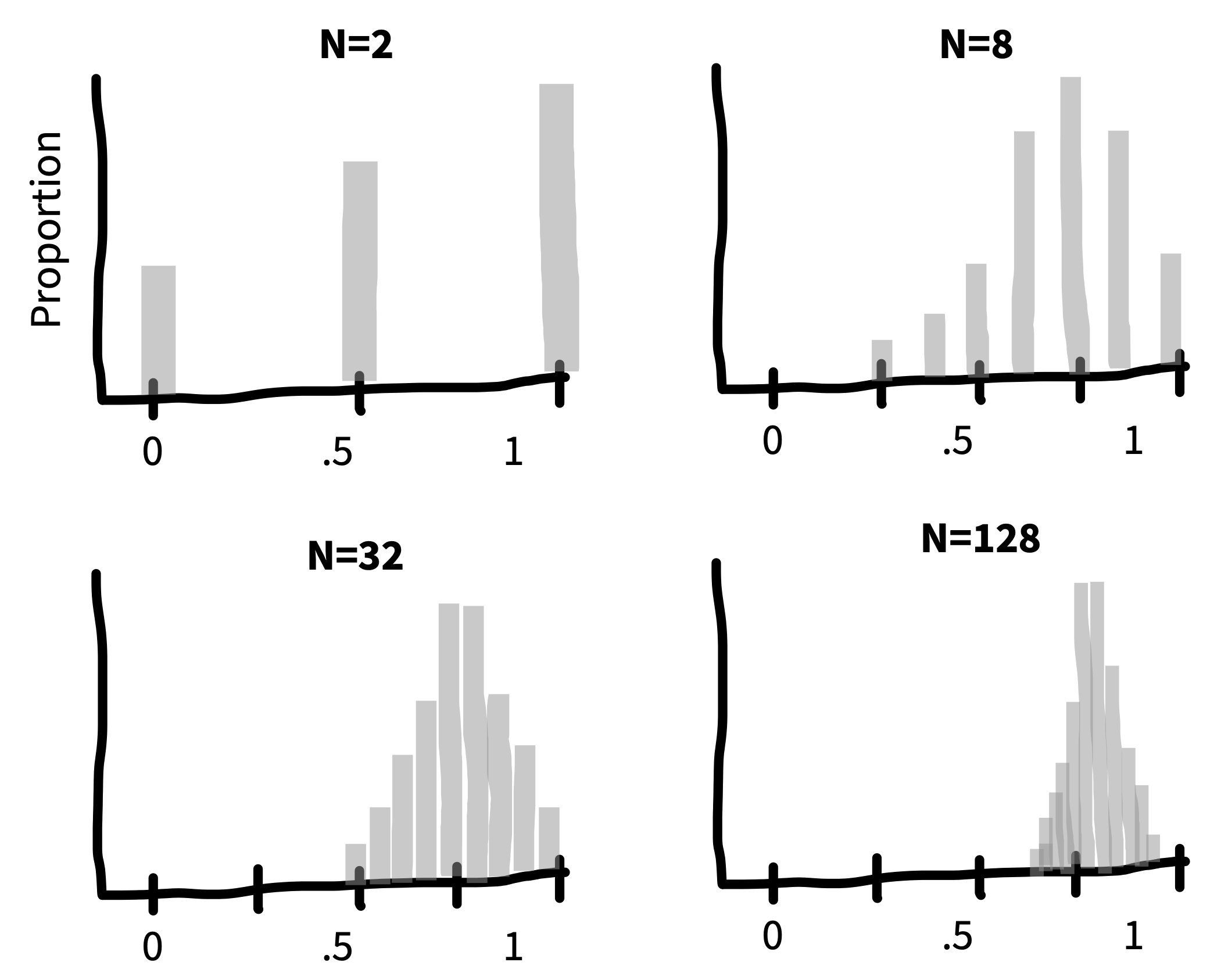
For example, say we are flipping a coin and we want to estimate the probability that it lands heads (\(p_H\)). If we draw samples each consisting of only \(n = 2\) coin flips, figure 6.4 is the sampling distribution of the estimates (\(\widehat{p}_H\)). This sampling distribution doesn’t look normally distributed at all—it doesn’t have the characteristic “bell curve” shape! In a sample of two coin flips, \(\widehat{p}_H\) can only take on the values \(0\), \(0.5\), or \(1\).
But look what happens as we draw increasingly larger samples in figure 6.5: we get a normal distribution! This tendency of sampling distributions to become normal as \(n\) becomes very large reflects a deep and elegant mathematical law called the central limit theorem.
The practical upshot is that the central limit theorem directly helps us characterize the uncertainty of sample estimates. For example, when the sample size is reasonably large (approximately \(n>30\) in the case of sample means) the standard error (i.e., the standard deviation of the sampling distribution) of a sample mean is approximately \(\widehat{\text{SE}} = \sigma/\sqrt{n}\). The sampling distribution becomes narrower as the sample size increases because we are dividing by the square root of the number of observations.
Notecode
Even though our figures are hand-drawn, they’re based on real simulations. For our central limit theorem simulations, we again use the map() function. We set up a tibble with the different values we want to to try (which we call n_flips). Then we make use of the map() function to run rbinom() (random binomial samples) for each value of n_flips.
One trick we make use of here is that rbinom() takes an extra argument that says how many of these random values you want to generate. Here we generate nsamps = 1000 samples, giving us 1,000 independent replicates at each n. But returning an array of 1,000 values for a single value of n_flips results in something odd: the value for each element of flips is an array. To deal with that, we use the unnest() function, which expands the array back into a normal tibble.
n_samps <- 1000
n_flips_list <- c(2, 8, 32, 128)
sample_p <- tibble(n_flips = n_flips_list) |>
mutate(flips = map(n_flips, \(f) rbinom(n = n_samps, size = f, prob = .7))) |>
unnest(cols = flips) |>
mutate(p = flips / n_flips)6.2 From variation to inference
Let’s go back to Fisher’s tea-tasting experiment. The first innovation of that experiment was the use of randomization to recover an estimate of the causal effect of milk ordering. But there was more to Fisher’s analysis than we described.
The second innovation of the tea-tasting experiment was the idea of creating a model of what might happen during the experiment. Specifically, Fisher described a hypothetical null model that would arise if the lady had chosen cups by chance rather than because of some tea sensitivity. In our tea-rating experiment, the null model describes what happens when there is no difference in ratings between tea-first and milk-first cups. Under the null model, the true treatment effect (\(\beta\)) is zero.
Even with an actual treatment effect of zero, across repeated sampling, we should see some variation in \(\widehat{\beta}\), our estimate of the treatment effect. Sometimes we’ll get a small positive effect, sometimes a small negative one. Occasionally just by chance we’ll get a big effect. This is just sampling variation as we described above.
Fisher’s innovation was to quantify the probability of observing various values of \(\hat{\beta}\), given the null model. Then, if the observed data that were very low probability under the null model, we could declare that the null was rejected. How unlikely must the observed data be in order to reject the null? Fisher declared that it is “usual and convenient for experimenters to take 5% as a standard level of convenience,” establishing the \(0.05\) cutoff that has become gospel throughout the sciences.4
4 Actually, right after establishing \(0.05\) as a cutoff, Fisher then writes that “in the statistical sense, we thereby admit that no isolated experiment, however significant in itself, can suffice for the experimental demonstration of any natural phenomenon … in order to assert that a natural phenomenon is experimentally demonstrable we need, not an isolated record, but a reliable method of procedure. In relation to the test of significance, we may say that a phenomenon is experimentally demonstrable when we know how to conduct an experiment which will rarely fail to give us a statistically significant result.” In other words, Fisher was all for replication!
Let’s take a look at what the null model might look like. We already tried out repeating our tea-tasting experiment thousands of times in our discussion of sampling above. Now in figure 6.6, we do the same thing but we assume that the null hypothesis of no treatment effect is true. The plot shows the distribution of treatment effects \(\hat{\beta}\) we observe: some a little negative, some a little positive, and a few substantially positive or negative, but mostly zero.
Let’s apply the \(p<0.05\) standard. If our observation has less than a 5% probability under the null model, then the null model is likely wrong. The red dashed lines on figure 6.6 show the point below which only 2.5% of the data are found and the point above which only 2.5% of the data are found. These are called the tails of the distribution. Because we’d be equally willing to accept milk-first tea or tea-first tea being better, we consider both positive and negative observations as possible.5
5 Because we’re looking at both tails of the distribution, this is called a “two-tailed” test.
Notecode
To simulate our null model, we can do the same kind of thing we did before, just specifying to our make_tea_data() function that the true difference in effects is zero!
n_sims <- 1000
null_model <- tibble(sim = 1:n_sims, n = 18) |>
mutate(data = map(sim, \(i) make_tea_data(n_total = n, delta = 0))) |>
unnest(cols = data)Again we use group_by() and summarize() to get the distribution of treatment effects under the null hypothesis.
null_model_summary <- null_model |>
group_by(sim, condition) |>
summarize(mean_rating = mean(rating)) |>
group_by(sim) |>
summarize(delta = mean_rating[condition == "milk first"] -
mean_rating[condition == "tea first"])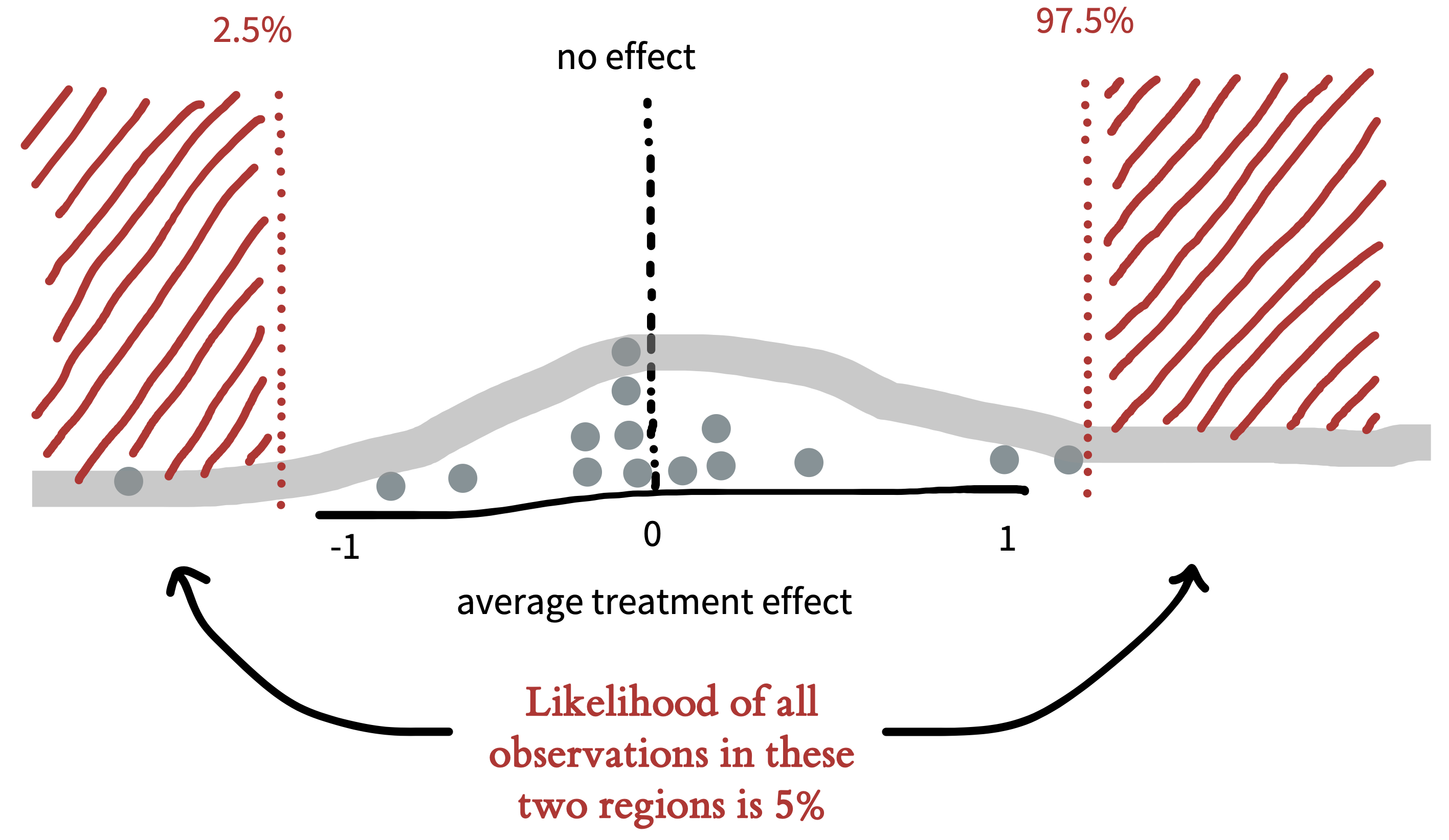
Figure 6.6 captures the logic of NHST: if the observed data fall in the region that has a probability of less than \(0.05\) under the null model, then we reject the null. So, then when we observe some particular treatment effect \(\hat{\beta}\) in a single (real) instance of our experiment, we can compute the probability of these data or any data more extreme than ours under the null model.6 This probability is our \(p\)-value, and if it is small, it gives us license to conclude that the null is false.
6 The “more extreme” part deserves a little explanation. Any individual outcome is relatively unlikely by itself, just because it’s surprising that the estimate is that exact value (we’re simplifying here, it gets a bit trickier when you are talking about real numbers). What we care about instead is a group of values. The ones that are in the middle of the distribution are, considered as a group, quite likely; the ones on the tails are, as a group, less likely. We want to know if the probability of the group of datapoints that includes our observation and anything even further out on the tails is collectively less than \(0.05\).
As we saw before, the larger the sample size, the smaller the standard error. That’s true for the null model too! Figure 6.7 shows the expected null distribution for a bigger experiment.
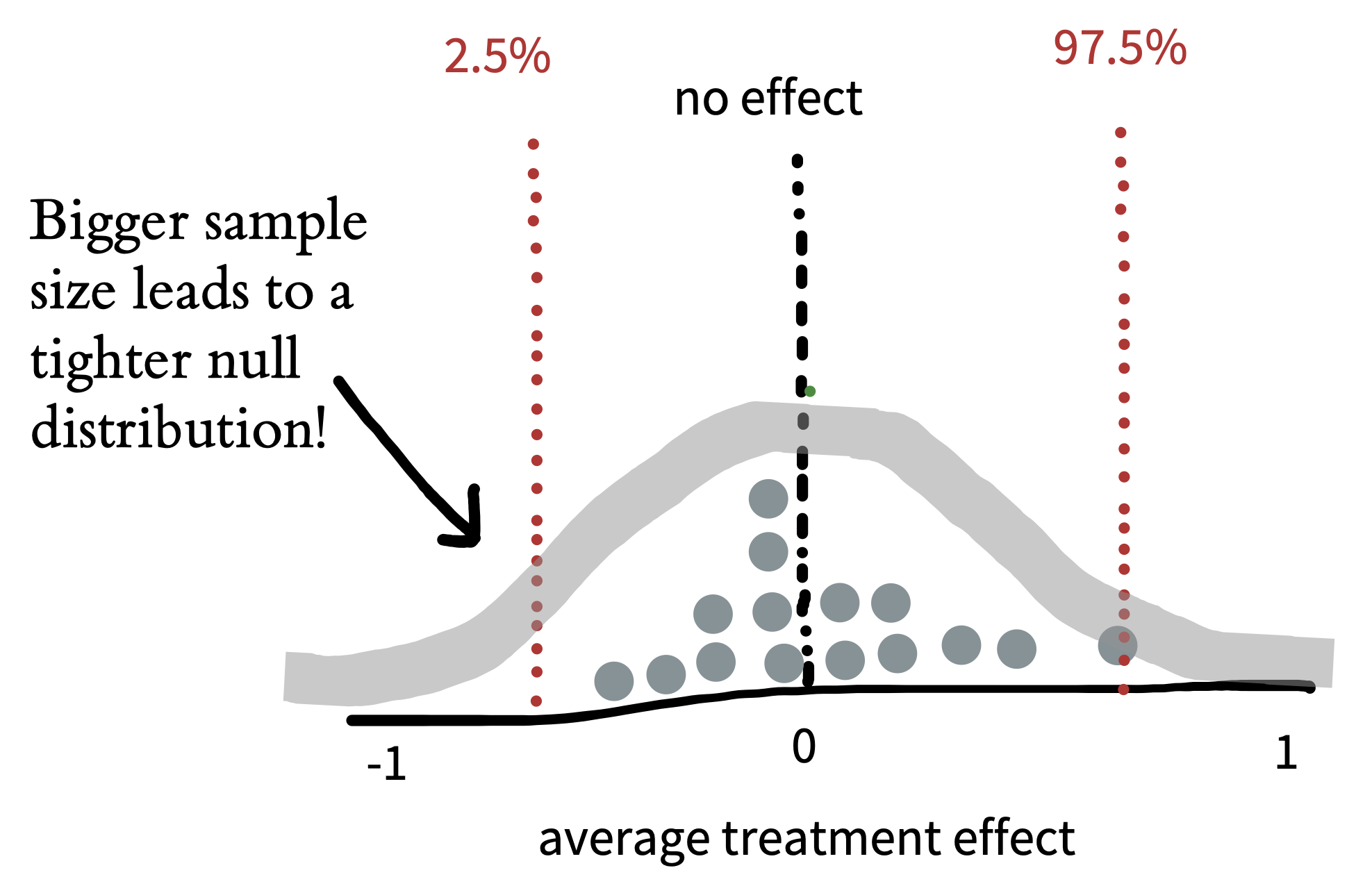
The more participants in the experiment, the tighter the null distribution becomes, and hence the smaller the region in which we should expect a null treatment effect to fall. Because our expectation based on the null becomes more precise, we will be able to reject the null based on smaller treatment effects. In this type of hypothesis testing, as with estimation, our goals matter. If we’re merely testing a hypothesis out of curiosity, perhaps we don’t want to measure too many cups of tea. But if we were designing the tea strategy for a major cafe chain, the stakes would be higher; in that case, maybe we’d want to do a more extensive experiment!
Notecode
We can do a more systematic simulation of the null regions for different sample sizes by simply adding a parameter to our simulation.
n_sims <- 10000
null_model_multi_n <- expand_grid(sim = 1:n_sims, n = c(12, 24, 48, 96)) |>
mutate(sim_data = map(n, \(n_i) make_tea_data(n_total = n_i, delta = 0))) |>
unnest(cols = sim_data)
null_model_summary_multi_n <- null_model_multi_n |>
group_by(n, sim, condition) |>
summarize(mean_rating = mean(rating)) |>
group_by(n, sim) |>
summarize(delta = mean_rating[condition == "milk first"] -
mean_rating[condition == "tea first"])
null_model_quantiles_multi_n <- null_model_summary_multi_n |>
group_by(n) |>
summarize(q_025 = quantile(delta, .025),
q_975 = quantile(delta, .975)) Here is the plotting code to produce a comparable figure to our illustration:
ggplot(null_model_summary_multi_n, aes(x = delta)) +
facet_wrap(vars(n), nrow = 1, labeller = label_both) +
geom_histogram(binwidth = .25) +
geom_vline(xintercept = 0, color = "grey", linetype = "dotted") +
geom_vline(data = null_model_quantiles_multi_n,
aes(xintercept = q_025), color = "red", linetype = "dotted") +
geom_vline(data = null_model_quantiles_multi_n,
aes(xintercept = q_975), color = "red", linetype = "dotted") +
xlim(-2.5, 2.5) +
labs(x = "Difference in rating", y = "Frequency")One last note: You might notice an interesting parallel between the NHST paradigm and Popper’s falsificationist philosophy (introduced in chapter 2). In both cases, you never get to accept the actual hypothesis of interest. The only thing you can do is observe evidence that is inconsistent with the null hypothesis. The added limitation of NHST is that the only hypothesis you can falsify is the null!7
7 A historical note: what we describe here as NHST is neither Fisher’s method or the Neyman-Pearson method that we introduce below. It’s what Gigerenzer (1989) called “the silent hybrid solution,” in which the more continuous approach to \(p\)-values that Fisher advocated for got rolled into the hypothesis testing approach of Neyman and Pearson. This hybrid—which neither Fisher nor Neyman and Pearson would have liked—is what we now mostly take for granted as the received NHST approach.
6.3 Making inferences
In the tea-tasting example we were just considering, we were trying to make an inference from our sample to the broader population. In particular, we were trying to test whether milk-first tea was rated as better than tea-first tea. Our inferential goal was a clear, binary answer: Is milk-first tea better?
By defining a \(p\)-value, we got one procedure for giving this answer. If \(p < 0.05\), we reject the null. Then we can look at the direction of the difference and, if it’s positive, declare that milk-first tea is “significantly” better. Let’s compare this procedure to a different process that builds on the Bayesian estimation ideas we described in the previous chapter. We can then come back to examine NHST in light of that framework.
6.3.1 Bayes Factors
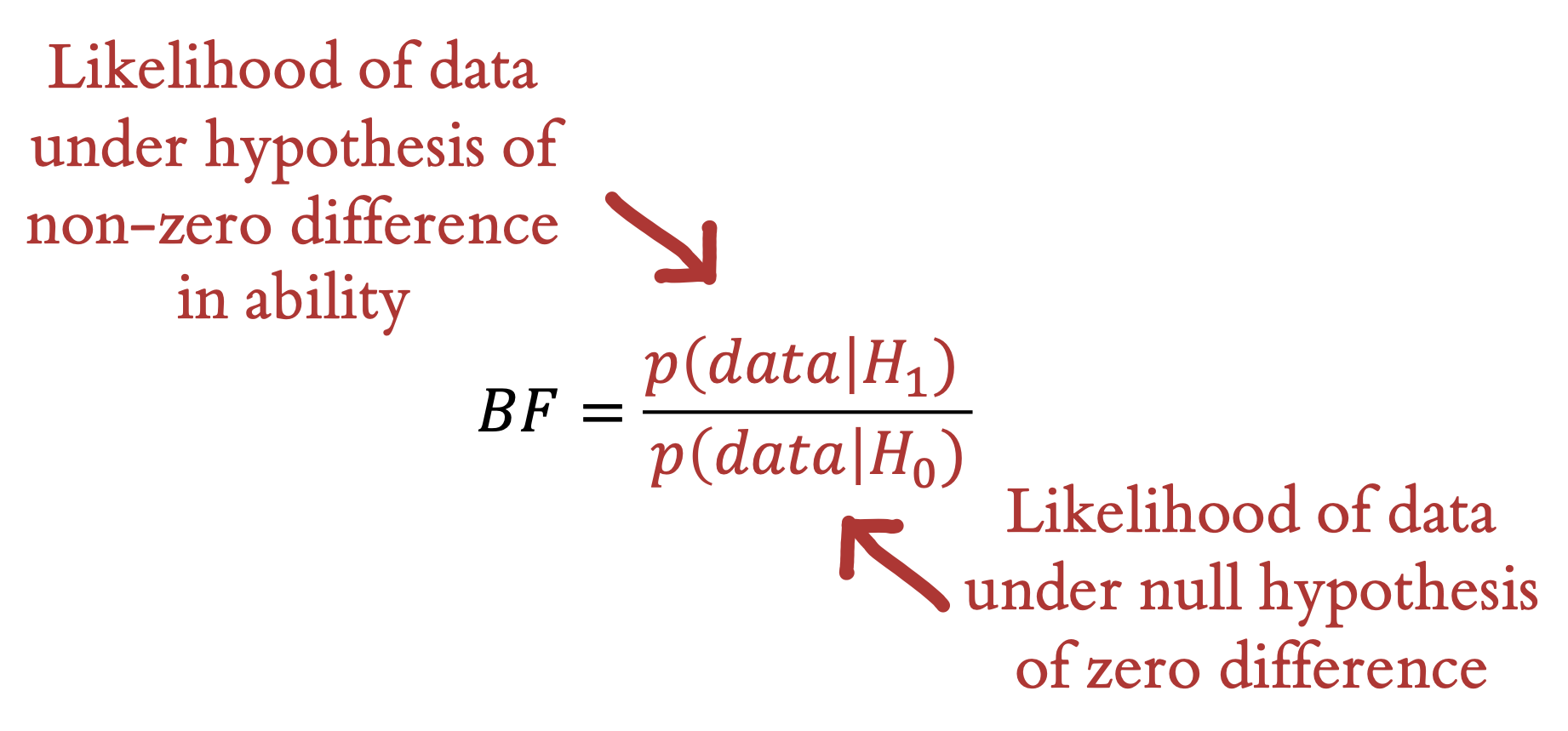
Bayes Factors are a method for quantifying the support for one hypothesis over another, based on an observed dataset. They don’t tell you the probability that a particular hypothesis is right, but they let you compare two different ones.
8 Sometimes people refer to the BF in favor of \(H_1\) as the \(\text{BF}_{10}\) and the BF in favor of \(H_0\) as the \(\text{BF}_{01}\). This notation is a bit confusing because the first of these looks like the number \(10\).
Informally, we’ve now discussed two different distinct hypotheses about the tea situation: our participants could have no tea discrimination ability—leading to chance performance. We call this \(H_0\). Or they could have some nonzero ability—leading to greater than chance performance. We call this \(H_1\). The Bayes Factor is simply the likelihood of the data (in the technical sense used above) under \(H_1\) vs under \(H_0\) (figure 6.8). The Bayes Factor is a ratio, so if it is greater than \(1\), the data are more likely under \(H_1\) than they are under \(H_0\)—and vice versa for values between \(1\) and \(0\). A BF of \(3\) means there is three times as much evidence for \(H_1\) than \(H_0\), or equivalently \(1/3\) as much evidence for \(H_0\) as \(H_1\).8
Notecode
Bayes Factors are delightfully easy to compute using the BayesFactor R package (Morey and Rouder 2023). All we do is feed in the two sets of ratings to the ttestBF() function!
library(BayesFactor)
tea_bf <- ttestBF(x = filter(tea_data, condition == "milk first")$rating,
y = filter(tea_data, condition == "tea first")$rating,
paired = FALSE)There are a couple of things to notice about the Bayes Factor. The first is that, like a \(p\)-value, it is inherently a continuous measure. You can artificially dichotomize decisions based on the Bayes Factor by declaring a cutoff (say, \(\text{BF} > 3\) or \(\text{BF} > 10\)), but there is no intrinsic threshold at which you would say the evidence is “significant.” Some guidelines for interpretation (from S. N. Goodman 1999) are shown in table 6.1.9 On the other hand, cutoffs like \(\text{BF} > 5\) or \(p < 0.05\) are not very informative. So, although we provide this table to guide interpretation, we caution that you should always report and interpret the actual Bayes Factor, not whether it is above or below some cutoff.
9 Some like the guidelines provided by Jeffreys (1961), which include categories such as “barely worth mentioning” (\(1 > \text{BF} > 3\)).
The second thing to notice about the Bayes Factor is that it doesn’t depend on our prior probability of \(H_1\) vs \(H_0\). We might think of \(H_1\) as very implausible. But the BF is independent of that prior belief. So that means it’s a measure of how much the evidence should shift our beliefs away from our prior. One nice way to think about this is that the Bayes Factor computes how much our beliefs—whatever they are—should be changed by the data (Morey and Rouder 2011).
In practice, the thing that is both tricky and good about Bayes Factors is that you need to define an actual model of what \(H_0\) and \(H_1\) are. That process involves making some assumptions explicit. We won’t go into how to make these models here—this is a big topic that is covered extensively in books on Bayesian data analysis.10 The goal here is just to give a general sense of what Bayes Factors are.
10 Two good ones beyond the McElreath book mentioned above are Gelman et al. (1995), which is a bit more statistical, and Kruschke (2014), which is a bit more focused on psychological data analysis. An in-prep web-book by Nicenboim, Schad, and Vasishth (2024) also looks great (https://bruno.nicenboim.me/bayescogsci).
6.3.2 \(p\)-values
Now let’s turn back to NHST and the \(p\)-value. We already have a working definition of what a \(p\)-value is from our discussion above: it’s the probability of the data (or any data that would be more extreme) under the null hypothesis. How is this quantity related to either our Bayesian estimate or the BF? Well, the first thing to notice is that the \(p\)-value is very close (but not identical) to the likelihood itself.11
11 The likelihood—for both Bayesians and frequentists—is the probability of the data, just like the \(p\)-value. But unlike the \(p\)-value, it doesn’t include the probability of more extreme data as well.
12 \(t\)-tests can also be used in cases where one sample is being compared to some baseline.
Next we can use a simple statistical test, a \(t\)-test, to compute \(p\)-values for our experiment. In case you haven’t encountered one, a \(t\)-test is a procedure for computing a \(p\)-value by comparing the distribution of two variables using the null hypothesis that there is no difference between them.12 The \(t\)-test uses the data to compute a test statistic whose distribution under the null hypothesis is known. Then the value of this statistic can be converted to \(p\)-values for making an inference.
Notecode
The standard t.test() function is built into R via the default stats package. Here we simply make sure to specify the variety of test we want by using the flags paired = FALSE and var.equal = TRUE (denoting the assumption of equal variances).
tea_t <- t.test(x = filter(tea_data, condition == "milk first")$rating,
y = filter(tea_data, condition == "tea first")$rating,
paired = FALSE, var.equal = TRUE)Imagine we conduct a tea-tasting experiment with \(n = 48\) and perform a \(t\)-test on our experimental results. In this case, we see that the difference between the two groups is significant at \(p<0.05\): \(t(46) = 2.86\), \(p = 0.006\).
The expression \(t(46) = 2.86\), \(p = 0.006\) is the standard way to report a \(t\)-test according to the American Psychological Association. The first part of this report gives the \(t\) value, qualified by the degrees of freedom for the test in parentheses. We won’t focus much on the idea of degrees of freedom here, but for now it’s enough to know that this number quantifies the amount of information given by the data, in this case 48 datapoints minus the two means (one for each of the samples).
Let’s compare \(p\)-values and Bayes Factors (computed using the default setup in the BayesFactor R package). In table 6.2, the rows represent simulated experiments with varying total numbers of participants (N) and varying average treatment effects. Both \(p\) and BF go up with more participants and larger effects. In general, BFs tend to be a bit more conservative than \(p\)-values, such that \(p<0.05\) can sometimes translate to a BF of less than 3 (Benjamin et al. 2018). For example, take a look at the row with 48 participants and an effect size of 1: the \(p\)-value is less than \(0.05\), but the Bayes Factor is only \(2.0\).
The critical thing about \(p\)-values, though, is not just that they are a kind of data likelihoods. It is that they are used in a specific inferential procedure. The logic of NHST is that we make a binary decision about the presence of an effect. If \(p < 0.05\), the null hypothesis is rejected; otherwise not. As Fisher (1949, 19) wrote,
It should be noted that the null hypothesis is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
The main problem with \(p\)-values from a scientific perspective is that researchers are usually interested in not just rejecting the null hypothesis but also in the evidence for the alternative (the one we are interested in). The Bayes Factor is one approach to quantifying positive evidence for the alternative hypothesis in a Bayesian framework. This issue with the Fisher approach to \(p\)-values has been known for a long time, though, and so there is an alternative frequentist approach as well.
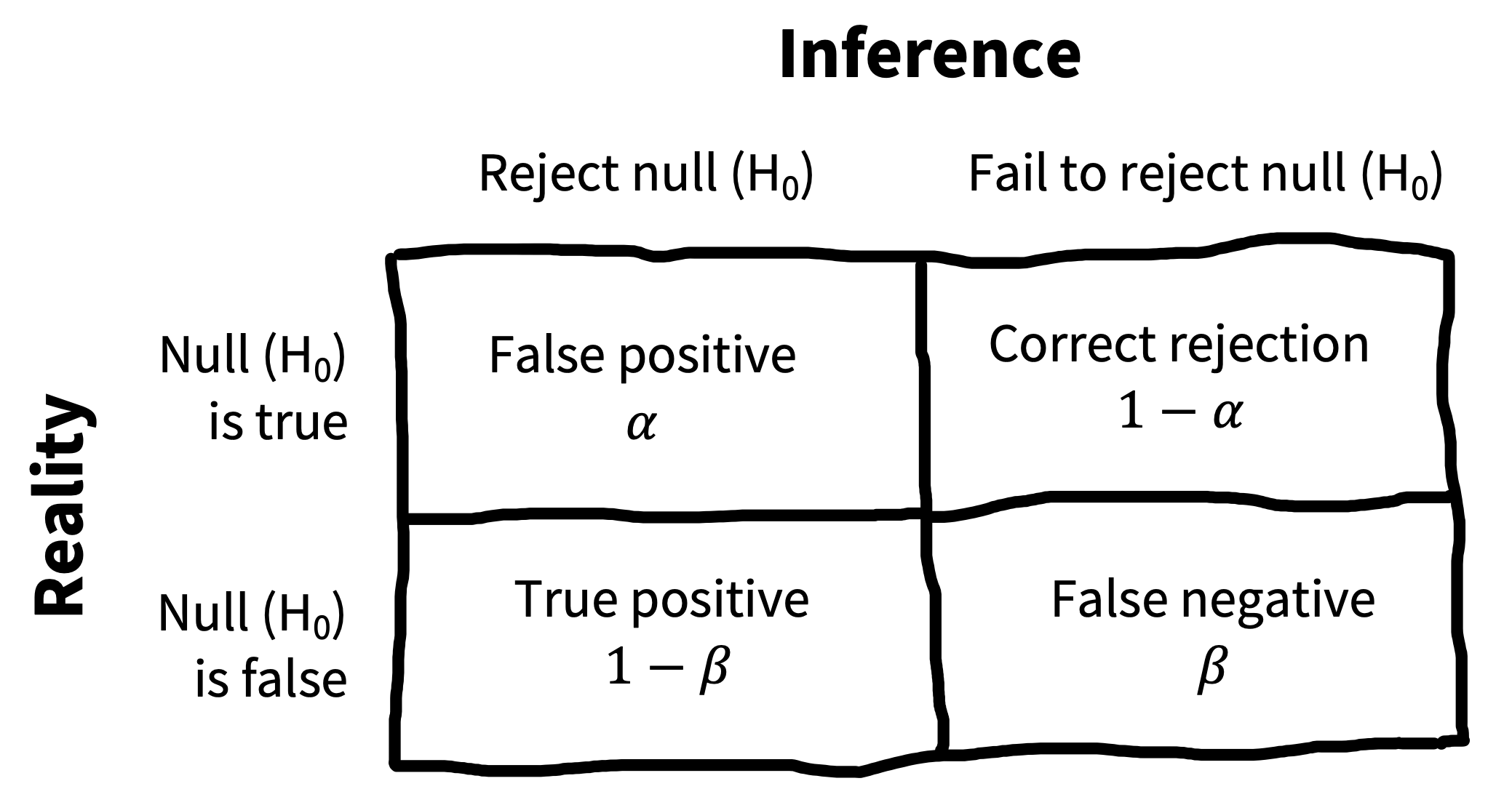
6.3.3 The Neyman-Pearson approach
One way to “patch” NHST is to introduce a decision-theoretic view, shown in figure 6.9.13 On this view, called the Neyman-Pearson view, there is a real \(H_1\), albeit one that is not specified. Then the true state of the world could be that \(H_0\) is true or \(H_1\) is true. The \(p<0.05\) criterion is the threshold at which we are willing to reject the null, and so this constitutes our false positive rate \(\alpha\). But we also need to define a false negative rate, which is conventionally called \(\beta\).14
13 A little bit of useful history here is given in Cohen (1990), and we also recommend Gigerenzer (1989) for a broader perspective.
14 Unfortunately, \(\beta\) is very commonly used for regression coefficients—and for that reason we’ve used it as our symbol for causal effects. We’ll be using these \(\beta\)s in the next chapter as well. Those \(\beta\)s are not to be confused with false negative rates. Sorry, this is just a place where statisticians have used the same Greek letter for two different things.
15 To make really rational decisions, you could couple this chart to some kind of utility function that assessed the costs of different outcomes. For example, you might think it’s worse to proceed with an intervention that doesn’t work than to stay with business as usual. In that case, you’d assign a higher cost to a false positive and accordingly try to adopt a more conservative criterion. We won’t cover this kind of decision analysis here, but Pratt et al. (1995) is a classic textbook on statistical decision theory if you’re interested.
Setting these rates is a decision problem: If you are too conservative in your criteria for the intervention having an effect, then you risk a false negative, where you incorrectly conclude that it doesn’t work. And if you’re too liberal in your assessment of the evidence, then you risk a false positive.15 In practice, however, people usually leave \(\alpha\) at \(0.05\) and try to control the false negative rate by increasing their sample size.
As we saw in figure 6.6, the larger the sample, the better your chance of rejecting the null for any given non-null effect. But these chances will depend also on the effect size you are estimating. This formulation gives rise to the idea of classical power analysis, which we cover in chapter 10. Most folks who defend binary inference are interested in using the Neyman-Pearson approach. In our view, this approach has its place (it’s especially useful for power analysis) but it still suffers from the substantial issues that plague all binary inference techniques.
Notedepth
Nonparametric resampling under the null
Hypothesis testing requires knowing the null distribution. In the examples above, it was easy to use statistical theory to work out the null distribution using knowledge of the binomial or normal distribution. But sometimes we don’t know what the null distribution would look like. What if the ratings data from our tea-tasting experiment were very skewed, such that there were many low ratings and a few very high ratings (as in figure 6.10)?
With skewed data like these, we couldn’t proceed with a \(t\)-test in good conscience because, with only \(n = 18\), we can’t necessarily trust that the central limit theorem has “kicked in” sufficiently for the test to work despite the skewness. Put another way, we can’t be sure that the null distribution is normal (Gaussian) in this case.
An alternative way to approximate a null distribution is through nonparametric resampling. Resampling means that we’re going to draw new samples from our existing sample, and nonparametric means that we will do this in a way that obviates assumptions about the shape of the null distribution—in contrast to parametric approaches that do rely on such assumptions). These techniques are sometimes called “bootstrapping” techniques.
The idea is, if the treatment truly had no effect on the outcome, then the observations would be exchangeable between the treatment and control groups. That is, there would not be systematic differences between the treatment and control groups. This property may or may not be true in our sample (that’s why we’re doing a hypothesis test in the first place), but we can draw new samples from our existing sample in a manner that forces exchangeability.
To perform this kind of test with our tea-tasting data, we would randomly shuffle the ratings in our dataset while leaving the condition assignments fixed. If we did this thousands of times and computed the treatment effect in each case, the result would be a null distribution: what we might expect the treatment effect to look like if there was no condition effect. In essence, we’re using a simulated version of “random assignment” here to break the dependency between the condition manipulation and the observed data.
We can then compare our actual treatment effect to this nonparametric null distribution. If the actual treatment was smaller than the 2.5th percentile or larger than the 97.5th percentile in the null distribution, we would reject the null with \(p < 0.05\), just the same as if we had used a \(t\)-test.
Resampling-based tests are extremely useful in a wide variety of cases. They can sometimes be less powerful than parametric approaches and they almost always require more computation, but their versatility makes them a great generic tool for data analysis.
6.4 Inference and its discontents
In earlier sections of this chapter, we reviewed NHST and Bayesian approaches to inference. Now it’s time to step back and think about some of the ways that inference practices—especially those related to NHST—have been problematic for psychology research. We’ll begin with some issues surrounding \(p\)-values and then give a specific accident report related to the process of “\(p\)-hacking” and some general philosophical discussion of how statistical testing relates to human reasoning.
6.4.1 Problems with the interpretation of \(p\)-values
\(p\)-values are basically likelihoods, in the sense we introduced in the previous chapter.16 They are the likelihood of the data under the null hypothesis! This likelihood is a critical number to know—for computing the Bayes Factor among other reasons. But it doesn’t tell us a lot of things that we might like to know!
16 The only thing that is different is the idea that they are the likelihood of the observed data or any more extreme.
For example, \(p\)-values don’t tell us the probability of the data under a specific alternative hypothesis that we might be interested in—that’s the posterior probability \(p(H_1 | \text{data})\). When our tea-tasting \(t\)-test yielded \(t(46) = 2.86\), \(p = 0.006\), that \(p\) is not the probability of the null hypothesis being true! And it’s definitely not the probability of milk-first tea being better.
What can you conclude when \(p>0.05\)? According to the classical logic of NHST, the answer is “nothing”! A failure to reject the null hypothesis doesn’t give you any additional evidence for the null. Even if the probability of the data (or some more extreme data) under \(H_0\) is high, their probability might be just as high or higher under \(H_1\).17 But many practicing researchers make this mistake. Aczel et al. (2018) coded a sample of articles from 2015 and found that 72% of negative statements were inconsistent with the logic of their statistical paradigm of choice—most were cases where researchers said that an effect was not present when they had simply failed to reject the null.
17 Of course, weighing these two against each other brings you back to the Bayes Factor.
These are not the only issues with \(p\)-values. In fact, people have so much trouble understanding what \(p\)-values do say that there are whole articles written about these misconceptions. Table 6.3 shows a set of misconceptions documented and refuted by S. N. Goodman (2008).
Let’s take a look at just a few. Misconception 1 is that, if \(p=0.05\), the null has a 5% chance of being true. This misconception is a result of confusing \(p(H_0 | \text{data})\) (the posterior) and \(p(\text{data} | H_0)\) (the likelihood—also known as the \(p\)-value). Misconception 2—that \(p > 0.05\) allows us to accept the null—also stems from this reversal of posterior and likelihood. And misconception 3 is a misinterpretation of the \(p\)-value as an effect size (which we learned about in the last chapter): a large effect is likely to be clinically important, but with a large enough sample size, you can get a small \(p\)-value even for a very small effect. We won’t go through all the misconceptions here, but we encourage you to challenge yourself to work through them (as in the exercise below).
| Misconception | |
|---|---|
| 1 | “If \(p = 0.05\), the null hypothesis has only a 5% chance of being true.” |
| 2 | “A nonsignificant difference (e.g., \(p \geq 0.05\)) means there is no difference between groups.” |
| 3 | “A statistically significant finding is clinically important.” |
| 4 | “Studies with \(p\)-values on opposite sides of \(0.05\) are conflicting.” |
| 5 | “Studies with the same \(p\)-value provide the same evidence against the null hypothesis.” |
| 6 | “\(p = 0.05\) means that we have observed data that would occur only 5% of the time under the null hypothesis.” |
| 7 | “\(p = 0.05\) and \(p \leq 0.05\) mean the same thing.” |
| 8 | “\(p\)-values are properly written as inequalities (e.g., ‘\(p \leq 0.02\)’ when \(p = 0.015\)).” |
| 9 | “\(p = 0.05\) means that if you reject the null hypothesis, the probability of a false positive error is only 5%.” |
| 10 | “With a \(p = 0.05\) threshold for significance, the chance of a false positive error will be 5%.” |
| 11 | “You should use a one-sided \(p\)-value when you don’t care about a result in one direction, or a difference in that direction is impossible.” |
| 12 | “A scientific conclusion or treatment policy should be based on whether or not the \(p\)-value is significant.” |
Beyond these misconceptions, there’s another problem. The \(p\)-value is a probability of a certain set of events happening (corresponding to the observed data or any “more extreme” data—that is to say, data further from the null). Since \(p\)-values are probabilities, we can combine them together across different events. If we run a “null experiment”—an experiment where the true effect is zero—the probability of a dataset with \(p < 0.05\) is of course \(0.05\). But if we run two such experiments, we can get \(p < 0.05\) with probability \(0.1\). By the time we run 20 experiments, we have an \(0.64\) chance of getting a positive result.
It would obviously be a major mistake to run 20 experiments and then report only the positive ones (which, by design, are false positives) as though these still were “statistically significant.” The same thing applies to doing 20 different statistical tests within a single experiment. There are many statistical corrections that can be made to adjust for this problem, which is known as the problem of multiple comparisons.18 But the the broader issue is one of transparency: unless you know what the appropriate set of experiments or tests is, it’s not possible to implement one of these corrections!19
18 The simplest and most versatile one, the Bonferroni correction, just divides \(0.05\) (or technically, whatever your threshold is) by the number of comparisons you are making. Using that correction, if you do 20 null experiments, you would have a 3% chance of a false positive.
19 This issue is especially problematic with \(p\)-values because they are so often presented as an independent set of tests, but the problem of multiple comparisons comes up when you compute a lot of independent Bayes Factors as well. “Posterior hacking” via selective reporting of Bayes Factors is perfectly possible (Simonsohn 2014).
Noteaccident report
Do extraordinary claims require extraordinary evidence?
In a blockbuster paper that may have inadvertently kicked off the replication crisis, Bem (2011) presented nine experiments he claimed provided evidence for precognition—that participants somehow had foreknowledge of the future. In the first of these experiments, Bem showed each of a group of 100 undergraduates 36 two-alternative forced choice trials in which they had to guess which of two locations on a screen would reveal a picture immediately before the picture was revealed. By chance, participants should choose the correct side 50% of the time of course. Bem found that, specifically for erotic pictures, participants’ guesses were 53.1% correct. This rate of guessing was unexpected under the null hypothesis of chance guessing (\(p = 0.01\)). Eight other studies with a total of more than 1,000 participants yielded apparently supportive evidence, with participants appearing to show a variety of psychological effects even before the stimuli were shown!
Based on this evidence, should we conclude that precognition exists? Probably not. Wagenmakers et al. (2011) presented a critique of Bem’s findings, arguing that (1) Bem’s experiments were exploratory (not preregistered) in nature, (2) that Bem’s conclusions were a priori unlikely, and (3) that the level of statistical evidence from his experiments was quite low. We find each of these arguments alone compelling; together they present a knockdown case against Bem’s interpretation.
First, we’ve already discussed the need to be skeptical about situations where experimenters have the opportunity for analytic flexibility in their choice of measures, manipulations, samples, and analyses. Flexibility leads to the possibility of cherry-picking those set of decisions from the “garden of forking paths” that lead to a positive outcome for the researcher’s favored hypothesis (for more details, see chapter 11). And there is plenty of flexibility on display even in experiment 1 of Bem’s paper. Although there were 100 participants in the study, they may have been combined post hoc from two distinct samples of 40 and 60, each of which saw different conditions. The 40 made guesses about the location of erotic, negative, and neutral pictures; the 60 saw erotic, positive non-romantic, and positive romantic pictures. The means of each of these conditions were presumably tested against chance (at least six comparisons, for a false positive rate of \(0.26\)). Had positive romantic pictures been found significant, Bem certainly could have interpreted this finding the same way he interpreted the erotic ones.
Second, as we discussed, a \(p\)-value close to \(0.05\) does not necessarily provide strong evidence against the null hypothesis. Wagenmakers et al. computed the Bayes Factor for each of the experiments in Bem’s paper and found that, in many cases, the amount of evidence for \(H_1\) was quite modest under a default Bayesian \(t\)-test. Experiment 1 was no exception: the BF was \(1.64\), giving only “anecdotal” support for the hypothesis of some nonzero effect, even before the multiple-comparisons problem mentioned above.
Finally, since precognition is not supported by any prior compelling scientific evidence (despite many attempts to obtain such evidence) and defies well-established physical laws, perhaps we should assign a low prior probability to Bem’s \(H_1\), a nonzero precognition effect. Taking a strong Bayesian position, Wagenmakers et al. suggest that we might do well to adopt a prior reflecting how unlikely precognition is, say \(p(H_1) = 10^{-20}\). And if we adopt this prior, even a very well-designed, highly informative experiment (with a Bayes Factor conveying substantial or even decisive evidence) would still lead to a very low posterior probability of precognition.
Wagenmakers et al. concluded that, rather than supporting precognition, the conclusion from Bem’s paper should be psychologists should revise how they think about analyzing their data (and avoid \(p\)-hacking)!
6.4.2 Philosophical (and empirical) views of probability
Up until now, we’ve presented Bayesian and frequentist tools as two different sets of computations. But, in fact, these different tools derive from fundamentally different philosophical perspectives on what a probability even is. Very roughly, frequentist approaches tend to believe that probabilities quantify the long-run frequencies of certain events. So, if we say that some outcome of an event has probability 0.5, we’re saying that if that event happened thousands of times, the long-run frequency of the outcome would be 50% of the total events. In contrast, the Bayesian viewpoint doesn’t depend on this sense that events could be exactly repeated. Instead, the subjective Bayesian interpretation of probability is that it quantifies a person’s degree of belief in a particular outcome.20
20 This is really a very rough description. If you’re interested in learning more about this philosophical background, we recommend the Stanford Encyclopedia of Philosophy entry, “Interpretations of Probability” (https://plato.stanford.edu/entries/probability-interpret).
You don’t have to take sides in this deep philosophical debate about what probability is. But it’s helpful to know that people actually seem to reason about the world in ways that are well described by the subjective Bayesian view of probability. Recent cognitive science research has made a lot of headway in describing reasoning as a process of Bayesian inference where probabilities describe degrees of belief in different hypotheses (for a textbook review of this approach, see N. D. Goodman, Tenenbaum, and The ProbMods Contributors 2016). These hypotheses in turn are a lot like the theories we described in chapter 2: they describe the relationships between different abstract entities (Tenenbaum et al. 2011). You might think that scientists are different from laypeople in this regard, but one of the striking findings from research on probabilistic reasoning and judgment is that expertise doesn’t matter that much. Statistically trained scientists—and even statisticians—make many of the same reasoning mistakes as their untrained students (Kahneman and Tversky 1979). Even children seem to reason intuitively in a way that looks a bit like Bayesian inference (Gopnik 2012).
These cognitive science findings help to explain some of the problems that people (scientists included) have in reasoning about \(p\)-values. If you are an intuitively Bayesian reasoner, the quantity that you’re probably tracking is how much you believe in your hypothesis (its posterior probability). So, many people treat the \(p\)-value as the posterior probability of the null hypothesis.21 That’s exactly what fallacy 1 in table 6.3 states—“If \(p = 0.05\), the null hypothesis has only a 5% chance of being true.” But this equivalence is incorrect! Written in math, \(p(\text{data} | H_0)\) (the likelihood that lets us compute the \(p\)-value) is not the same thing as \(p(H_0 | \text{data})\) (the posterior that we want). Pulling from our accident report above, even if the probability of the observed ESP data given the null hypothesis is low, that doesn’t mean that the probability of ESP is high.
21 Cohen (1994) is a great treatment of this issue.
6.4.3 What framework to use?
The problem with binary inferences is that they enable behaviors that can introduce bias into the scientific ecosystem. By the logic of statistical significance, either an experiment “worked” or it didn’t. Because everyone would usually rather have an experiment that worked than one that didn’t, inference criteria like \(p\)-values often become a target for selection, as we discussed in chapter 3.22
22 More generally, this pattern is probably an example of Goodhart’s law, which says that when a measure becomes a target, it’s no longer a good measure (Strathern 1997). Once the outcomes of statistical inference procedures become targets for publication, they are subject to selection biases—e.g., \(p\)-hacking—that make them less meaningful.
If you want to quantify evidence for or against a hypothesis, it’s worth considering whether Bayes Factors address your question better than \(p\)-values. In practice, \(p\)-values are hard to understand and often misused—though to be fair, BFs are misused plenty too. These issues may be rooted in basic facts about how humans reason about probability.
Despite the reasons to be worried about \(p\)-values, for many practicing scientists (at least at time of writing), there is no one right answer about whether to use them or not. Even if we’d like to be Bayesian all the time, there are a number of obstacles. First, though new computational tools make fitting Bayesian models and extracting Bayes Factors much easier than before, it’s still on average quite a bit harder to fit a Bayesian model than it is a frequentist one. Second, because Bayesian analyses are less familiar, it may be an uphill battle to convince advisors, reviewers, and funders to use them.
As a group of authors, some of us are more Bayesian than frequentist, while others are more frequentist than Bayesian—but all of us recognize the need to move between statistical paradigms depending on the problem we’re working on. Furthermore, a lot of the time we’re not so worried about which paradigm we’re using. The paradigms are at their most divergent when making binary inferences, and they often look much more similar when they are used in the context of quantifying measurement precision.
6.5 Computing precision
Our last section presented an argument against using \(p\)-values for making dichotomous inferences. But we still want to move from what we know about our own limited sample to some inference about the population. How should we do this?
6.5.1 Confidence intervals
One alternative to binary hypothesis testing is to ask about the precision of our estimates—how similar an estimate from a particular sample is to the population parameter of interest. For example, how close is our tea-tasting effect estimate to the true effect in the population? We don’t know what the true effect is, but knowledge of sampling distributions lets us make some guesses about how precise our estimate is.
The confidence interval is a convenient frequentist way to summarize the variability of the sampling distribution—and hence how precise our point estimate is. The confidence interval represents the range of possible values for the parameter of interest that are plausible given the data. More formally, a 95% confidence interval for some estimate (call it \(\widehat{\beta}\), as in our example) is defined as a range of possible values for \(\beta\) such that, if we did repeated sampling, 95% of the intervals generated by those samples would contain the true parameter, \(\beta\).
Confidence intervals (CIs) are constructed by estimating the middle 95% of the sampling distribution of \(\widehat{\beta}\). Because of our hero, the central limit theorem, we can treat the sampling distribution as normal for reasonably large samples. Given this, it’s common to construct a 95% confidence interval \(\widehat{\beta} \pm 1.96 \; \widehat{\text{SE}}\).23 If we were to conduct the experiment 100 times and calculate a confidence interval each time, we should expect 95 of the intervals to contain the true \(\beta\), whereas we would expect the remaining 5 to not contain \(\beta\).24
23 This type of CI is called a “Wald” confidence interval.
24 In case you don’t have enough tea to do the experiment 100 times to confirm this, you can do it virtually using this nice simulation tool: https://istats.shinyapps.io/ExploreCoverage.
Confidence intervals are like betting on the inferences drawn from your sample. The sample you drew is like one pull of a slot machine that will pay off (i.e., have the confidence interval contain the true parameter) 95% of the time. Put more concisely: 95% of 95% confidence intervals contain the true value of the population parameter.
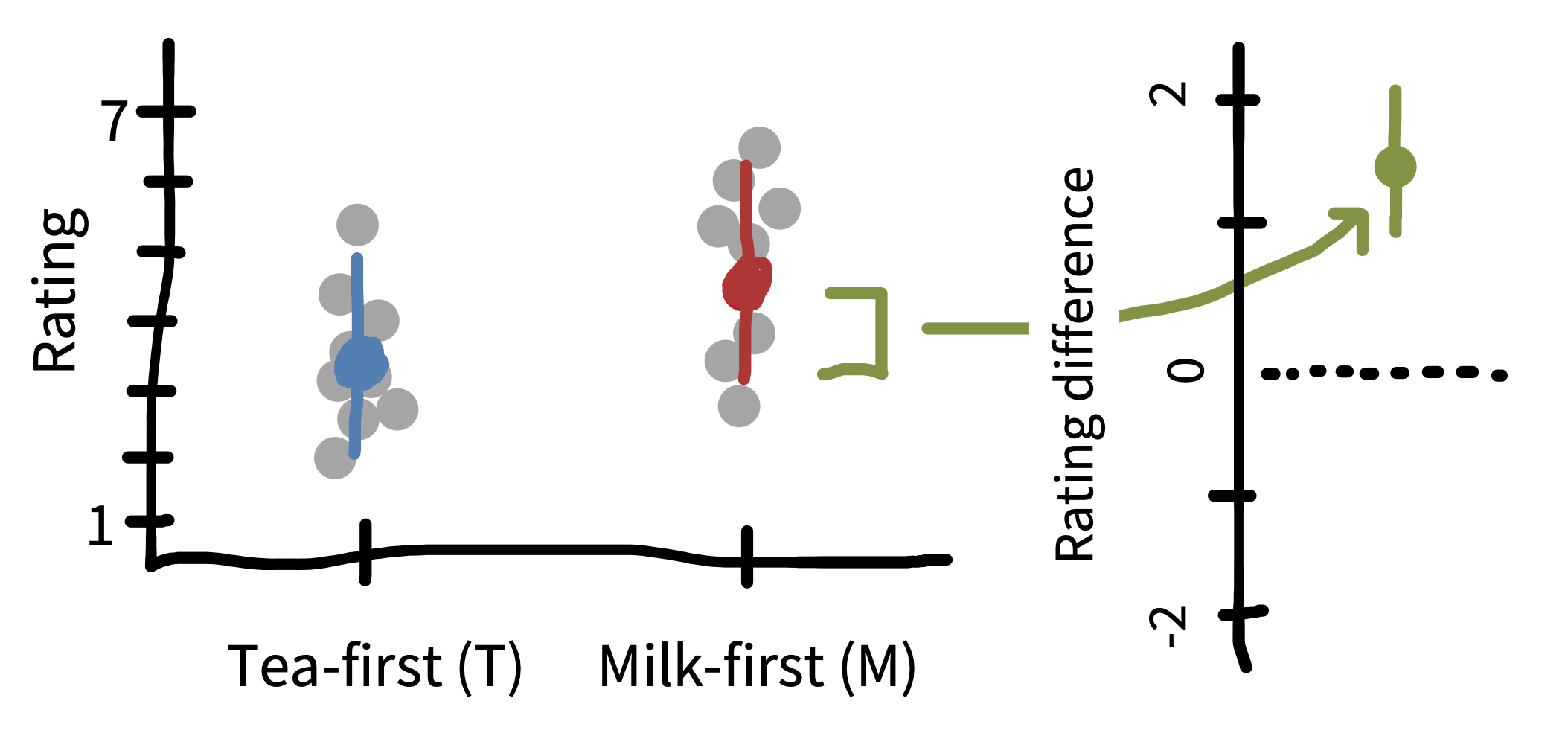
For visualization, we can show the confidence intervals on individual estimates (left side of figure 6.11). These tell us about the precision of our estimates of each quantity relative to the population estimate. But we’ve been talking primarily about the CI on the treatment effect \(\widehat{\beta}\) (right side of figure 6.11). This CI allows us to make an inference about whether or not it overlaps with zero—which is actually equivalent in this case to whether or not the \(t\)-test is statistically significant.
Notecode
Computing confidence intervals analytically is pretty easy. Here we first compute the standard error for the difference between conditions. The only tricky bit here is that we need to compute a pooled standard deviation.
tea_ratings <- filter(tea_data, condition == "tea first")$rating
milk_ratings <- filter(tea_data, condition == "milk first")$rating
n_tea <- length(tea_ratings)
n_milk <- length(milk_ratings)
sd_tea <- sd(tea_ratings)
sd_milk <- sd(milk_ratings)
tea_sd_pooled <- sqrt(((n_tea - 1) * sd_tea ^ 2 + (n_milk - 1) * sd_milk ^ 2) /
(n_tea + n_milk - 2))
tea_se <- tea_sd_pooled * sqrt((1 / n_tea) + (1 / n_milk))Once we have the standard error, we can get the estimated difference between conditions and compute the confidence intervals by multiplying the standard error by 1.96.
delta_hat <- mean(milk_ratings) - mean(tea_ratings)
tea_ci_lower <- delta_hat - tea_se * qnorm(0.975)
tea_ci_upper <- delta_hat + tea_se * qnorm(0.975)6.5.2 Confidence in confidence intervals?
Confidence intervals are often misinterpreted by students and researchers alike (Hoekstra et al. 2014). Imagine a researcher conducts an experiment and reports that “the 95% confidence interval for the mean ranges from \(0.1\) to \(0.4\).” All of the statements in table 6.4, though tempting to make about this situation, are technically false.
| Misconception | |
|---|---|
| 1 | “The probability that the true mean is greater than \(0\) is at least 95%.” |
| 2 | “The probability that the true mean equals \(0\) is smaller than 5%.” |
| 3 | “The ‘null hypothesis’ that the true mean equals \(0\) is likely to be incorrect.” |
| 4 | “There is a 95% probability that the true mean lies between \(0.1\) and \(0.4\).” |
| 5 | “We can be 95% confident that the true mean lies between \(0.1\) and \(0.4\).” |
| 6 | “If we were to repeat the experiment over and over, then 95% of the time the true mean falls between \(0.1\) and \(0.4\).” |
The problem with all of these statements is that, in the frequentist framework, there is only one true value of the population parameter, and the variability captured in confidence intervals is about the samples, not the parameter itself.25 For this reason, we can’t make any statements about the probability of the value of the parameter or of our confidence in specific numbers. To reiterate, what we can say is: if we were to repeat the procedure of conducting the experiment and calculating a confidence interval many times, in the long run, 95% of those confidence intervals would contain the true parameter.
25 In contrast, Bayesians think of parameters themselves as variable rather than fixed.
The Bayesian analog to a confidence interval is a credible interval. Recall that for Bayesians, parameters themselves are considered probabilistic (i.e., subject to random variation), not fixed. A 95% credible interval for an estimate, \(\widehat{\beta}\), represents a range of possible values for \(\beta\) such that there is a 95% probability that \(\beta\) falls inside the interval. Because we are now wearing our Bayesian hats, we are “allowed” to talk about \(\beta\) as if it were probabilistic rather than fixed. In practice, credible intervals are constructed by finding the posterior distribution of \(\beta\), as in chapter 5, and then taking the middle 95%, for example.
Credible intervals are nice because they don’t give rise to many of the inference fallacies surrounding confidence intervals. They actually do represent our beliefs about where \(\beta\) is likely to be, for example. Despite the technical differences between credible intervals and confidence intervals, in practice—with larger sample sizes and weaker priors—they turn out to be quite similar to each other in many cases.26
26 They can diverge sharply in cases with less data or stronger priors (Morey et al. 2016), but in our experience this is relatively rare.
6.6 Chapter summary: Inference
Inference tools help you move from characteristics of the sample to characteristics of the population. This move is a critical part of generalization from research data. But we hope we’ve convinced you that inference doesn’t have to mean making a binary decision about the presence or absence of an effect. A strategy that seeks to estimate an effect and its associated precision is often much more helpful as a building block for theory. As we move toward estimating causal effects in more complex experimental designs, the process will require more sophisticated models. Toward that goal, the next chapter provides some guidance for how to build such models.
Notediscussion questions
Can you write the definition of a \(p\)-value and a Bayes Factor without looking them up? Try this out—what parts of the definitions did you get wrong?
Take three of Goodman’s (2008) “dirty dozen” in table 6.3 and write a description of why each is a misconception. (These can be checked against the original article, which gives a nice discussion of each.)
Notereadings
Many of the concepts described here are illustrated beautifully via interactive visualizations. We recommend https://seeing-theory.brown.edu for a broad overview of statistical concepts and https://rpsychologist.com/viz for a number of interactives that specifically illustrate concepts discussed in this chapter and the previous one, including \(p\)-values, effect sizes, maximum likelihood estimation, confidence intervals, and Bayesian inference.
A fun, polemical critique of NHST: Cohen, Jacob (1994). “The Earth is Round (\(p < .05\)).” American Psychologist 49 (12):997–1003. https://doi.org/10.1037/0003-066X.49.12.997.
A nice introduction to Bayesian data analysis: Kruschke, John K., and Torrin M. Liddell (2018a). “Bayesian Data Analysis for Newcomers.” Psychonomic Bulletin & Review 25 (1): 155–-177. https://doi.org/10.3758/s13423-017-1272-1.
Aczel, Balazs, Bence Palfi, Aba Szollosi, Marton Kovacs, Barnabas Szaszi, Peter Szecsi, Mark Zrubka, Quentin F Gronau, Don van den Bergh, and Eric-Jan Wagenmakers. 2018. “Quantifying Support for the Null Hypothesis in Psychology: An Empirical Investigation.” Advances in Methods and Practices in Psychological Science 1 (3): 357–66.
Bem, Daryl J. 2011. “Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect.” Journal of Personality and Social Psychology 100 (3): 407.
Benjamin, Daniel J., James O. Berger, Magnus Johannesson, Brian A. Nosek, E. -J. Wagenmakers, Richard Berk, Kenneth A. Bollen, et al. 2018. “Redefine Statistical Significance.” Nature Human Behaviour 2 (1): 6–10. https://doi.org/10.1038/s41562-017-0189-z.
Cohen, Jacob. 1990. “Things I Have Learned (So Far).” American Psychologist 45: 1304–12.
———. 1994. “The Earth is Round (p < .05).” American Psychologist 49 (12): 997–1003. https://doi.org/10.1037/0003-066X.49.12.997.
Cumming, Geoff. 2014. “The New Statistics: Why and How.” Psychological Science 25 (1): 7–29.
Fisher, Ronald A. 1949. The Design of Experiments. 5th ed. Oliver & Boyd.
Gelman, Andrew, John B Carlin, Hal S Stern, and Donald B Rubin. 1995. Bayesian Data Analysis. Chapman & Hall/CRC.
Gelman, Andrew, and Jennifer Hill. 2006. Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press.
Gelman, Andrew, Jennifer Hill, and Aki Vehtari. 2020. Regression and Other Stories. Cambridge University Press.
Gigerenzer, Gerd. 1989. The Empire of Chance: How Probability Changed Science and Everyday Life. 12. Cambridge University Press.
Goodman, Noah D., Joshua B. Tenenbaum, and The ProbMods Contributors. 2016. “Probabilistic Models of Cognition.” http://probmods.org/.
Goodman, Steven N. 1999. “Toward Evidence-Based Medical Statistics. 2: The Bayes Factor.” Annals of Internal Medicine 130 (12): 1005–13.
———. 2008. “A Dirty Dozen: Twelve p-Value Misconceptions.” In Seminars in Hematology, 45:135–40. 3. Elsevier.
Gopnik, Alison. 2012. “Scientific Thinking in Young Children: Theoretical Advances, Empirical Research, and Policy Implications.” Science 337 (6102): 1623–27.
Hoekstra, Rink, Richard D Morey, Jeffrey N Rouder, and Eric-Jan Wagenmakers. 2014. “Robust Misinterpretation of Confidence Intervals.” Psychonomic Bulletin & Review 21 (5): 1157–64.
Jeffreys, Harold. 1961. The Theory of Probability. 3rd ed. OUP Oxford.
Kahneman, Daniel, and Amos Tversky. 1979. “Prospect Theory: An Analysis of Decision under Risk.” Econometrica 47 (2): 363–91.
Kruschke, John K. 2014. Doing Bayesian Data Analysis: A Tutorial with r, JAGS, and Stan. Academic Press.
Kruschke, John K, and Torrin M Liddell. 2018a. “Bayesian Data Analysis for Newcomers.” Psychonomic Bulletin & Review 25 (1): 155–77.
———. 2018b. “The Bayesian New Statistics: Hypothesis Testing, Estimation, Meta-Analysis, and Power Analysis from a Bayesian Perspective.” Psychonomic Bulletin & Review 25 (1): 178–206.
McElreath, Richard. 2018. Statistical Rethinking: A Bayesian Course with Examples in R and Stan. Chapman & Hall/CRC.
Morey, Richard D, Rink Hoekstra, Jeffrey N Rouder, Michael D Lee, and Eric-Jan Wagenmakers. 2016. “The Fallacy of Placing Confidence in Confidence Intervals.” Psychonomic Bulletin & Review 23 (1): 103–23.
Morey, Richard D, and Jeffrey N Rouder. 2011. “Bayes Factor Approaches for Testing Interval Null Hypotheses.” Psychological Methods 16 (4): 406.
———. 2023. BayesFactor: Computation of Bayes Factors for Common Designs. https://CRAN.R-project.org/package=BayesFactor.
Nicenboim, Bruno, Schad Daniel, and Shravan Vasishth. 2024. An Introduction to Bayesian Data Analysis for Cognitive Science. https://vasishth.github.io/bayescogsci/book/.
Pratt, John Winsor, Howard Raiffa, Robert Schlaifer, et al. 1995. Introduction to Statistical Decision Theory. MIT Press.
Simonsohn, Uri. 2014. “Posterior-Hacking: Selective Reporting Invalidates Bayesian Results Also.” https://doi.org/10.2139/ssrn.2374040.
Strathern, Marilyn. 1997. “‘Improving Ratings’: Audit in the British University System.” European Review 5 (3): 305–21.
Tenenbaum, Joshua B, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. 2011. “How to Grow a Mind: Statistics, Structure, and Abstraction.” Science 331 (6022): 1279–85.
Wagenmakers, Eric-Jan, Ruud Wetzels, Denny Borsboom, and Han L J Van Der Maas. 2011. “Why Psychologists Must Change the Way They Analyze Their Data: The Case of Psi: Comment on Bem (2011).” Journal of Personality and Social Psychology 100 (3): 426–32. https://doi.org/10.1037/a0022790.