9 Design
- Describe key elements of experimental design
- Define randomization and counterbalancing strategies for removing confounds
- Discuss strategies to design experiments that are appropriate to the populations of interest
The key thesis of our book is that experiments should be designed to yield precise and unbiased measurements of a causal effect. But the causal effect of what? The manipulation! In an experiment we manipulate (intervene on) some aspect of the world and measure the effects of that manipulation. We then compare that measurement to a situation where the intervention has not occurred.
We refer to different intervention states as conditions of the experiment. The most common experimental design is the comparison between a control condition, in which the intervention is not performed, and an experimental (sometimes called treatment) condition in which the intervention is performed.
But many other experimental designs are possible. In more complex experiments, manipulations along different dimensions (sometimes called factors in this context) can be combined. In the first part of the chapter, we’ll introduce some common experimental designs and the vocabulary for describing them. Our focus here is in identifying designs that maximize measurement precision.
A good experimental measure must be a valid measure of the construct of interest. The same is true for a manipulation—it must validly relate to the causal effect of interest. In the second part of the chapter, we’ll discuss issues of manipulation validity, including both issues of ecological validity and confounding. We’ll talk about how practices like randomization and counterbalancing can help remove nuisance confounds, an important part of bias reduction for experimental designs.1
1 This section will draw on our introduction to causal inference in chapter 1, so if you haven’t read that, now’s the time.
To preview our general take-home points from this chapter: we think that your default experiment should manipulate one or two factors—usually not more—and should manipulate those factors continuously and within participants. Although such designs are not always possible, they are typically the most likely to yield precise estimates of a particular effect that can be used to constrain future theorizing. We’ll start by considering a case study in which a subtle confound led to difficulties interpreting an experimental result.
Automatic theory of mind?
In an early version of our course, student Desmond Ong set out to replicate a thought-provoking finding: both infants and adults seemed to show evidence of tracking other agents’ belief state, even when it was irrelevant to the task at hand (Kovács, Téglás, and Endress 2010). In the paradigm, an animated Smurf character would watch as a self-propelled ball came in and out from behind a screen. At the end of the video, the screen would swing down and the participant had to respond whether the ball was present or absent. Reaction time for this decision was the key dependent variable.
The experimental design investigated two factors: whether the participant believed the ball was present or absent (P+/P−) and whether the animated agent would have believed the ball was present or absent (A+/A−) based on what it saw. The result was four conditions: P+/A+, P+/A−, P−/A+, and P−/A−. (We could call this a fully-crossed design because each level of one factor was presented with each level of the other.)
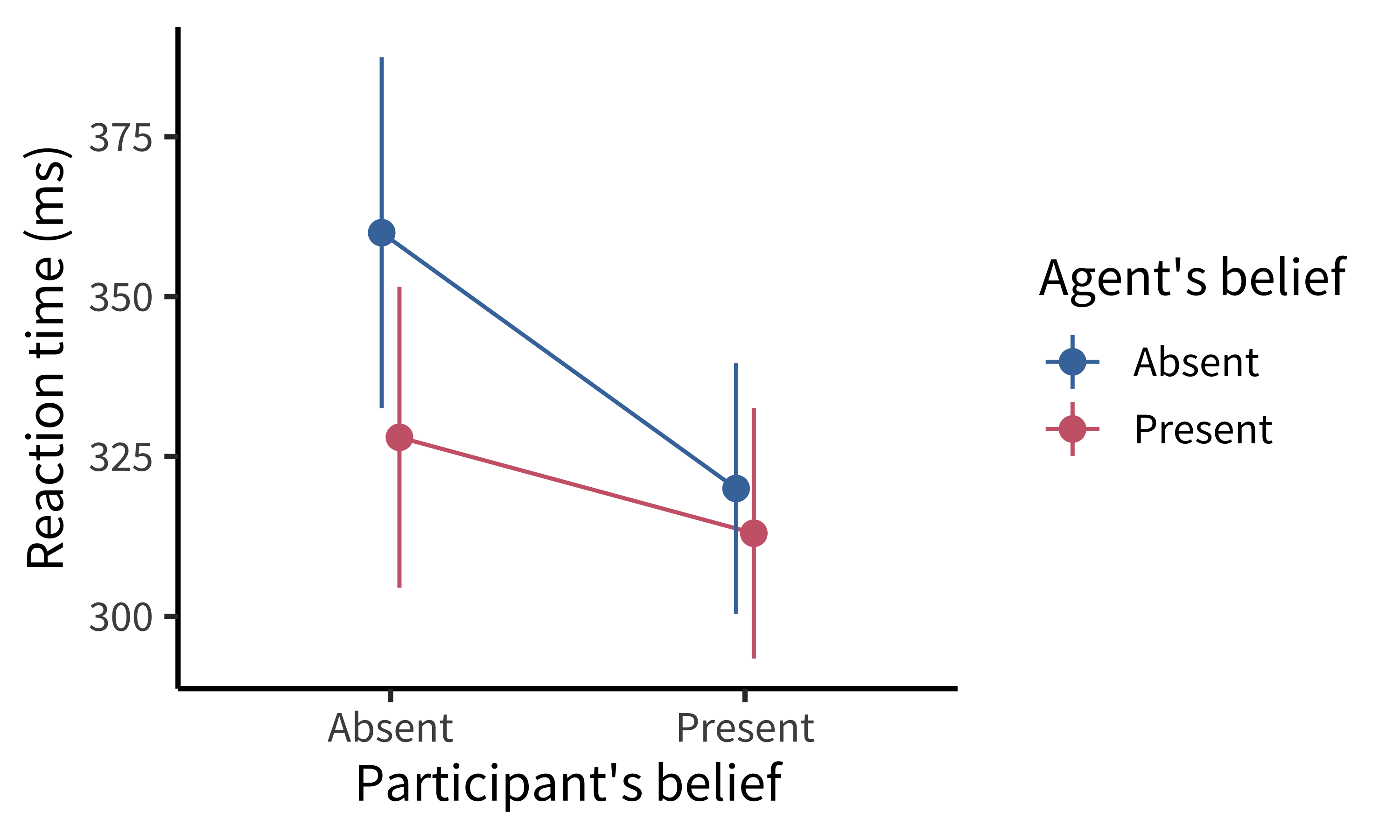
Both the original experiments and the replication that Desmond ran showed a significant effect of the agent’s beliefs on participants’ reaction times, suggesting that what the—totally irrelevant—agent thought about the ball was leading them to react more or less quickly to the presence of the ball. Figure 9.1 shows the original data (\(N = 24\)). But, although both studies showed an effect of agent belief, the replication and several variations also showed a crossover interaction of participant and agent belief. The participants were slower when the agents and the participants believed that the ball was behind the screen (figure 9.2). That finding wasn’t consistent with the theory that tracking inconsistent beliefs slowed down reaction times. If participants were tracking their own beliefs about the ball and the agent’s, they should have been fastest in the P+/A+ condition, not slower.
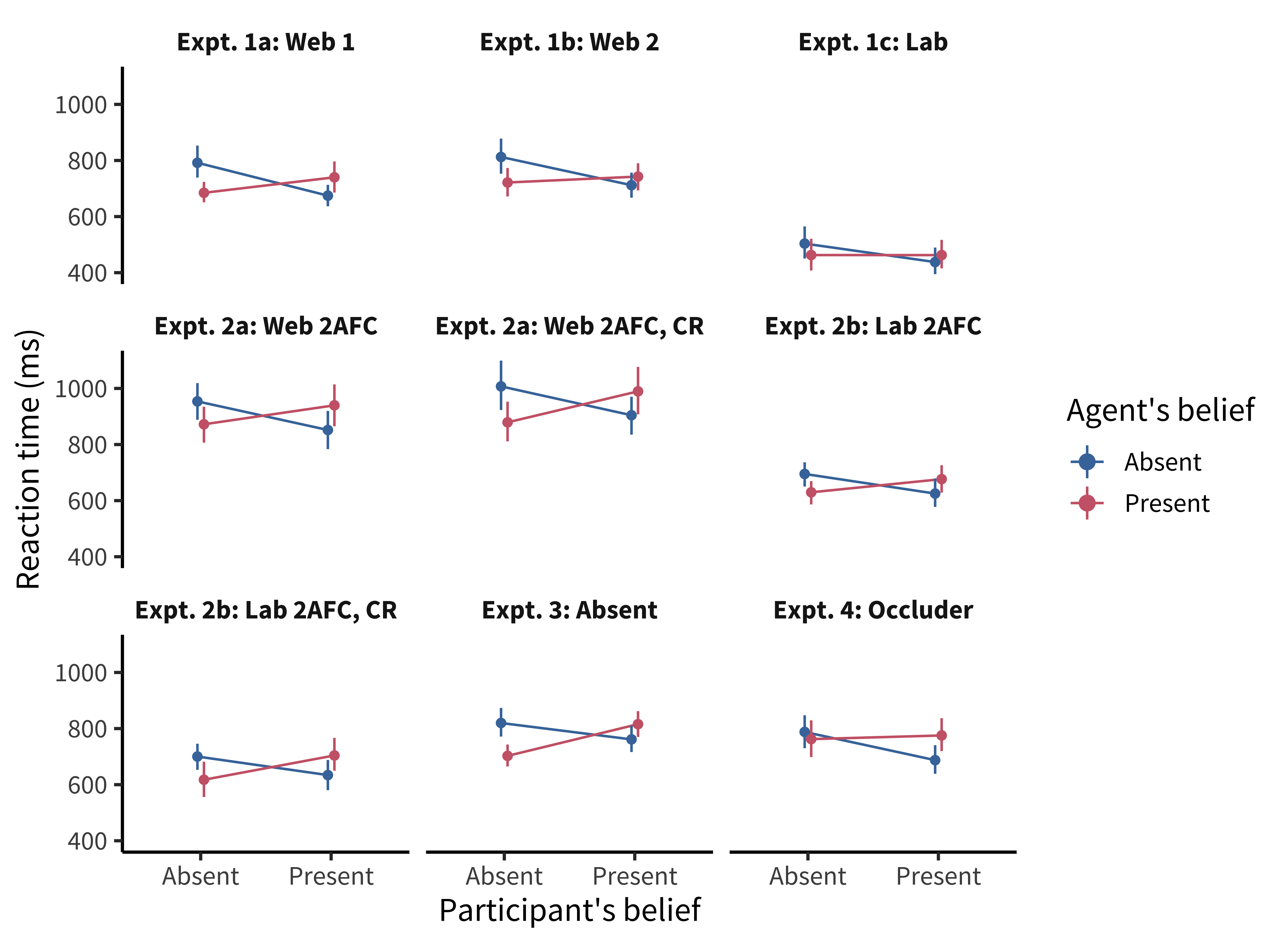
A collaborative team working on this paradigm identified a key issue (Phillips et al. 2015). There was a confound in the experimental design—another factor that varied across conditions besides the target factors. In other words, something was changing between conditions other than the agent’s and participant’s belief states. The confound was an attention check (discussed further in chapter 12): participants had to press a key when the agent left the scene to show that they were paying attention. This attention check appeared a few seconds later in the videos for the P+/A+ and P−/A− trials—the ones that yielded the slow reaction times—than it did for the other two. When the attention check was removed or when its timing was equalized across conditions, reaction time effects were eliminated, suggesting that the original pattern of findings may have been due to the confound.
If the standard for replication is significance of particular statistical tests at \(p < 0.05\), then this experiment replicated successfully. But the effect estimates were inconsistent with the proposed theoretical explanation. A finding can be replicable without providing support for the underlying theory!
There’s an important caveat to this story. The followup work only revealed that there was a confound in one particular experimental operationalization and did not provide evidence against automatic theory of mind in general. Indeed, others have suggested that different versions of this paradigm do reveal evidence for theory of mind processing once the confound is eliminated (El Kaddouri et al. 2020).
9.1 Experimental designs
Experimental designs are fundamental to many fields; unfortunately, the terminology used to describe them can vary, which can get quite confusing! Here we will mostly describe an experiment as a relationship between some manipulation(s), in which participants are randomly assigned to experimental conditions to estimate effects on some measure. Factors are the dimensions along which manipulations vary. For example, in our case study above, the two factors were participant belief and agent belief. Another terminology it’s good to be familiar with is the terms used in chapters 5–7, which are often used in econometrics and statistics: treatment (manipulation) and outcome (measure).2
2 Terminology here is hard. In psychology people sometimes say there’s an independent variable (the manipulation, which is causally prior and hence “independent” of other causal influences) and a dependent variable (the measure, which causally depends on the manipulation, or so we hypothesize). We find this terminology to be hard to remember because the terms are so different from the actual concepts being described.
In this section, we’ll discuss key dimensions on which experiments vary: (1) how many factors they incorporate and how these factors are crossed; (2) how many conditions and measures are given to each participant; and (3) if manipulations have discrete levels or fall on a continuous scale.
9.1.1 A two-factor experiment
The classical “design of experiments” framework has as its goal to separate observed variability in the dependent measure into (1) variability due to the manipulation(s) and (2) other variability, including measurement error and participant-level variation. This framework maps nicely onto the statistical framework described in chapters 5–7. In essence, this framework models the distribution of the measure using the condition structure of our experiment as the predictor.
Different experimental designs will allow us to estimate specific effects more and less effectively. Recall in chapter 5, we estimated the effect of our tea/milk order manipulation by a simple subtraction: \(\beta = \theta_{T} - \theta_{C}\) (where \(\beta\) is the effect estimate, and each \(\theta\) indicates the estimates for a condition, treatment \(T\) and control \(C\); we called them \(\theta_T\) and \(\theta_M\) in that chapter to denote tea- and milk-first conditions). This logic works just fine also if there are two distinct treatments in a three-condition experiment: each treatment can be compared to control separately. For treatment 1, \(\beta_{T_1} = \theta_{T_1} - \theta_{C}\) and \(\beta_{T_2} = \theta_{T_2} - \theta_{C}\).
This logic is going to get more complicated if we have more than one distinct factor of interest, though. Let’s look at an example.
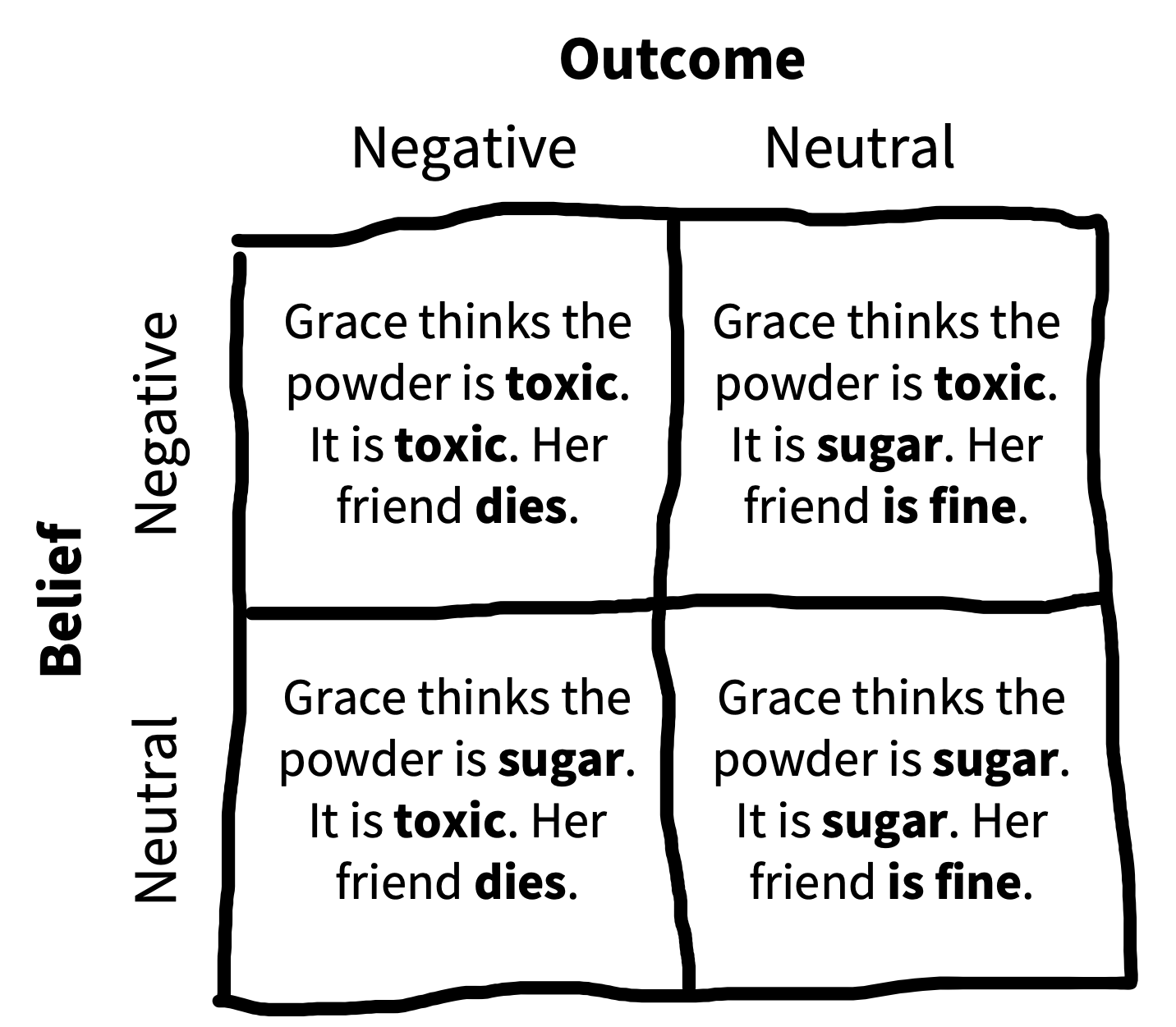
Young et al. (2007) were interested in how moral judgments depend on both the beliefs of actors and the outcomes of their actions. They presented participants with vignettes in which they learned, for example, that Grace visits a chemical factory with her friend and goes to the coffee break room, where she sees a white powder that she puts in her friend’s coffee. They then manipulated both Grace’s beliefs and the outcomes of her action following the schema in figure 9.3. Participants (\(N = 10\)) used a four-point Likert scale to rate whether the actions were morally forbidden (1) or permissible (4). Figure 9.4 shows the data.
Young et al.’s design has two factors—belief and outcome—each with two levels (neutral and negative, noted as \(B\) and \(-B\) for belief and \(O\) and \(-O\) for outcome).3 These factors are fully crossed: each level of each factor is combined with each level of each other.
3 Neither of these is necessarily a “control” condition: the goal is simply to compare these two levels of the factor—negative and neutral—to estimate the effect due to the factor.
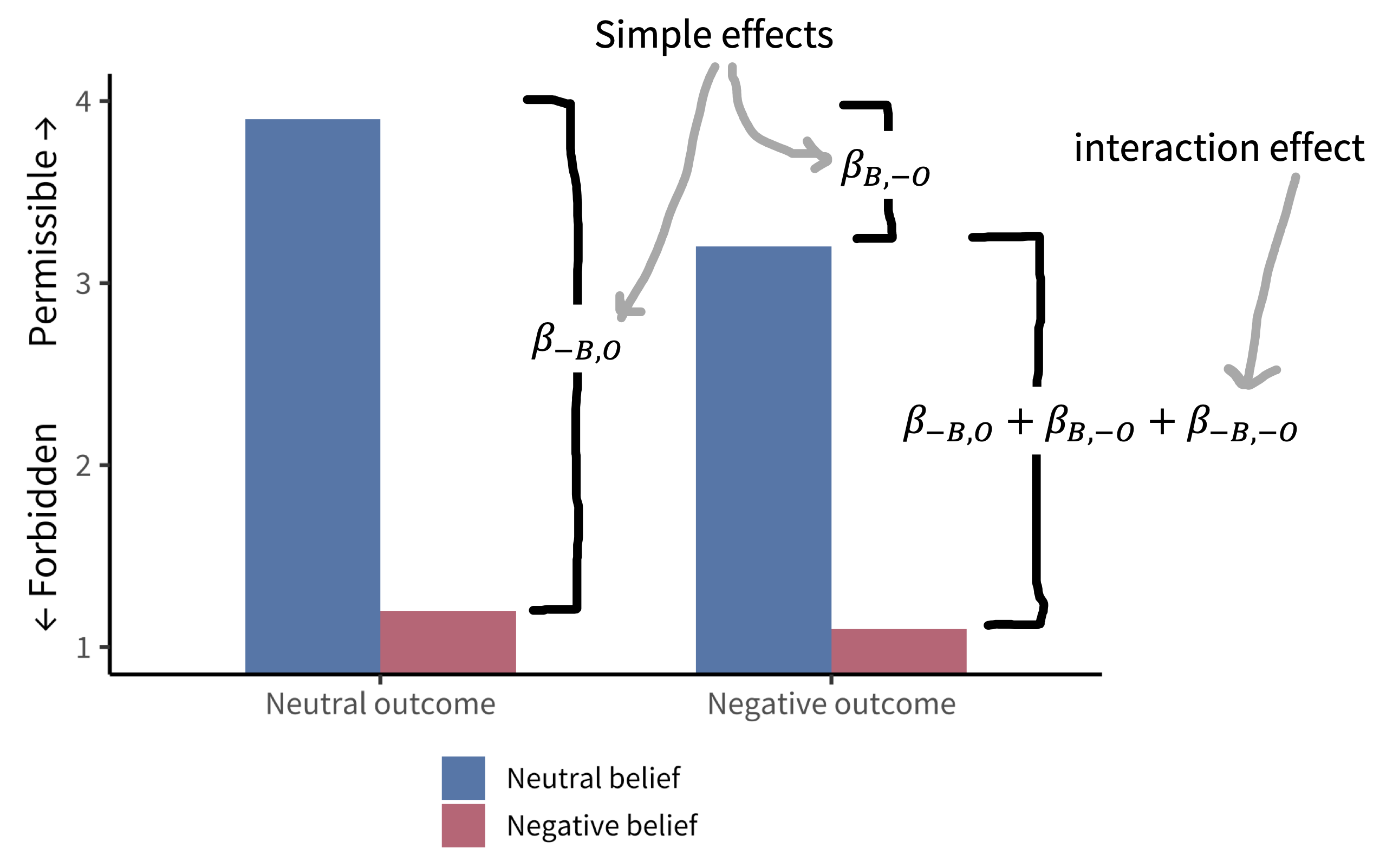
This fully-crossed design makes it easy for us to estimate quantities of interest. Let’s say that our reference group (equivalent to the control group for now) is neutral belief, neutral outcome. Now it’s easy to use the same kind of subtraction we did before to estimate particular effects we care about. For example, we can look at the effect of negative belief in the case of a neutral outcome: \(\beta_{-B,O} = \theta_{-B,O} - \theta_{B,O}\). This effect is shown on the left side of figure 9.4.
But now there is a complexity: these two simple effects (effects of one variable at a particular level of another variable) together suggest that the combined effect \(\beta_{-B,-O}\) in the negative belief, negative outcome condition should be equal to the sum of \(\beta_{-B,O}\) and \(\beta_{B,-O}\).4 As we can see from figure 9.4, that’s not right. If it were, the negative belief, negative outcome condition would be below the lowest possible rating!
4 If you’re interested, you can also compute the average or main effect of a particular factor via the same subtractive logic. For example, the average effect of negative belief (\(-B\)) vs a neutral belief (\(B\)) can be computed as\(\beta_{-B} = \frac{(\theta_{-O, -B}\ +\ \theta_{O, -B})\ -\ (\theta_{-O, B}\ +\ \theta_{O, B})}{2}\).
5 If you’re reading carefully, you may be thinking that this sounds like we’re talking about analysis of variance (ANOVA), not about experimental design per se. These two topics are actually the same topic! The question is how to design an experiment so that these statistical models can be used to estimate particular effects—and combinations of effects—that we care about. In case you missed it, we discuss modeling interactions in a regression framework in chapter 7.
Instead, we observe an interaction effect (sometimes called a two-way interaction when there are two factors): the effect when both factors are present is different than the sum of the two simple effects. To capture this effect, we need an interaction term: \(\beta_{-B,-O}\).5 In other words, the effect of negative beliefs (intent) on subjective moral permissibility depends on whether the action caused harm. Critically, without a fully-crossed design, we can’t estimate this interaction and we would have made an incorrect prediction about one condition.
9.1.2 Generalized factorial designs
Young et al.’s design, in which there are two factors with two levels each, is called a 2 x 2 design (pronounced “two by two”). These 2 x 2 designs are incredibly common and useful, but they are only one of an infinite variety of such designs that can be constructed.
Say we added a third factor to Young et al.’s design such that Grace either feels neutral toward her friend or is angry on that day. If we fully crossed this third factor \(A\) with the other two (\(B\) and \(O\)), we’d have a 2 x 2 x 2 design. This design would have eight conditions: \((A, B, O)\), \((A, B, -O)\), \((A, -B, O)\), \((A, -B, -O)\), \((-A, B, O)\), \((-A, B, -O)\), \((-A, -B, O)\), \((-A, -B, -O)\). These conditions would allow us to estimate both two-way and three-way interactions (listed in table 9.1).
Three-way interactions are hard to think about! The affect x belief x outcome interaction tells you about the difference in moral permissibility that’s due to all three factors being present as opposed to what you’d predict on the basis of your estimates of the two-way interactions. In addition to being hard to think about, higher-order interactions tend to be hard to estimate, because estimating them accurately requires you to have a stable estimate of all of the lower-order interactions (McClelland and Judd 1993). For this reason, we recommend against experimental designs that rely on higher-order interactions unless you are in a situation where you both have strong predictions about these interactions and are confident in your ability to estimate them appropriately.
Things can get even more complicated. If you have three factors with two levels each, as in the example above (table 9.1), you can estimate seven total effects of interest. But if you have four factors with two levels each, you get 15. Four factors with three levels each gets you a horrifying 80 different effects!6 This way lies madness, at least from the perspective of estimating and interpreting individual effects in a reasonable sample size. Again, we suggest starting with one- and two-factor designs. There is a lot to be learned from simple designs that follow good measurement and sampling practices.
6 The general formula for \(N\) factors with \(M\) levels each is \(M^N-1\).
Estimation strategies for generalized factorial designs
So, what should you do if you really do care about four or more factors—in the sense that you want to estimate their effects and include them in your theory? The simplest strategy is to start your research off by measuring them independently in a series of single-factor experiments. This kind of setup is natural when there is a single reference level for each factor of interest, and such experiments can provide a basis for judging which factors are most important for your outcome and, hence, which should be prioritized for experiments to estimate interactions.
On the other hand, sometimes there is no reference level for a factor. For example, in the Kovács, Téglás, and Endress (2010) paradigm, it’s not clear whether a positive or negative belief is the reference level. That’s not a problem in a fully-crossed design like theirs, but this situation can pose a problem if you have more than two such factors. Ideally you would want to run independent experiments, but you have to choose some level for all of the other variables—you can’t just assume that one level is “neutral.”
One solution that lets you compute main effects but not interactions is called a Latin square. Latin squares are a good solution for three-factor designs, which is the level at which a fully-crossed design typically gets overwhelming. A Latin square is an \(n\ \text{x}\ n\) matrix in which each number occurs exactly once in each row and column, for example: \[\begin{bmatrix} 1 & 2 & 3 \\ 2 & 3 & 1\\ 3 & 1 & 2 \\ \end{bmatrix}\] This Latin square for \(n = 3\) gives the solution for how to balance factors across a 3 x 3 x 3 experiment. The row number is one factor, the column number is the second factor, and the number in the cell is the third factor. So one condition would be \((1,1,1)\), the first level of all factors, shown in the upper left cell. Another would be \((3,3,2)\), the lower right cell. Although a fully-crossed design would require 27 cells to be run, the Latin square has only nine. Critically, the combinations of factors are balanced across the nine cells so that the average effect of each level of the three factors can be estimated.
There are also fancier methods available. For example, the literature on optimal experiment design contains methods for choosing the most informative sequence of experiments to run in order to estimate the parameters in a model that can include many factors and their interactions (Myung and Pitt 2009). Going down this road typically means having an implemented computational theory of your domain, but it can be a very productive strategy for exploring a complex experimental space with many factors.
9.1.3 Between- vs within-participant designs
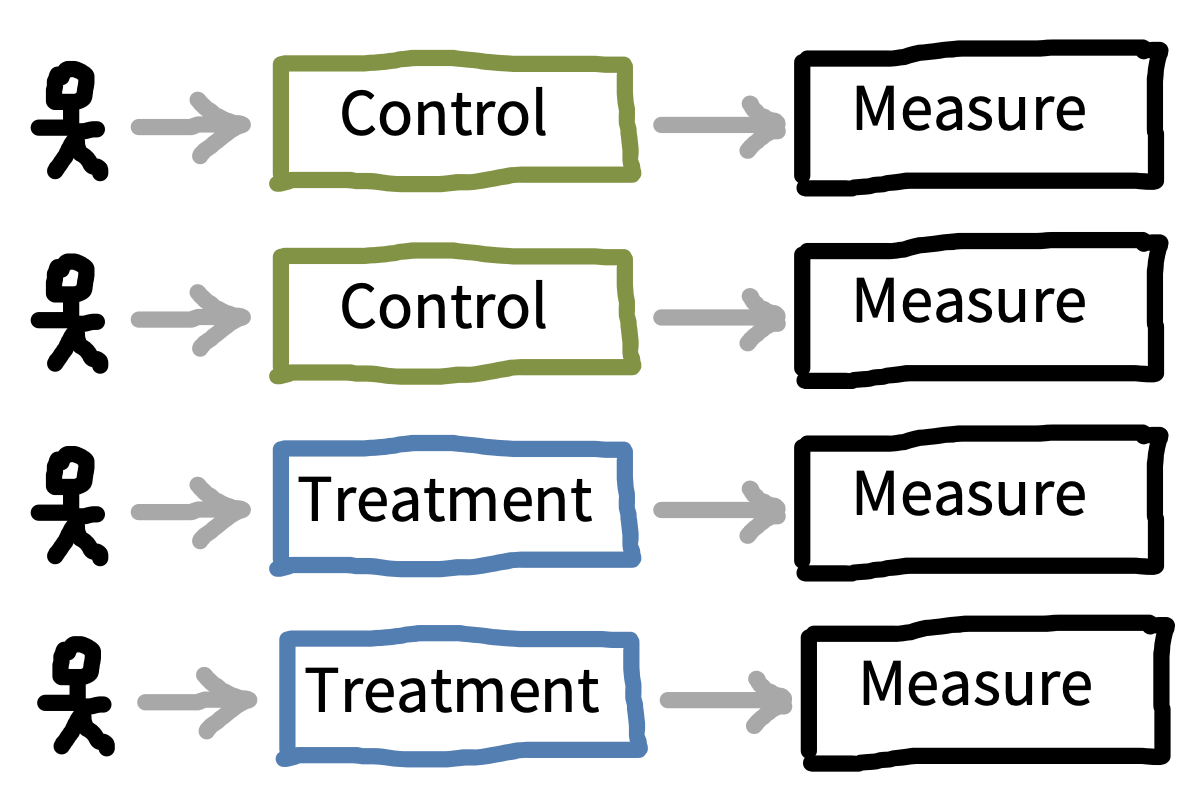
Once you know what factor(s) you would like to manipulate in your experiment, the next step is to consider how these will be presented to participants, and how that presentation will interact with your measurements. The biggest decision to be made is whether each participant will experience one level of a factor—a between-participants design—or whether they will experience multiple levels—a within-participants design. Figure 9.5 shows a simple example of between-participants design with four participants (two assigned to each condition), while figure 9.6 shows a within-participants version of the same design.
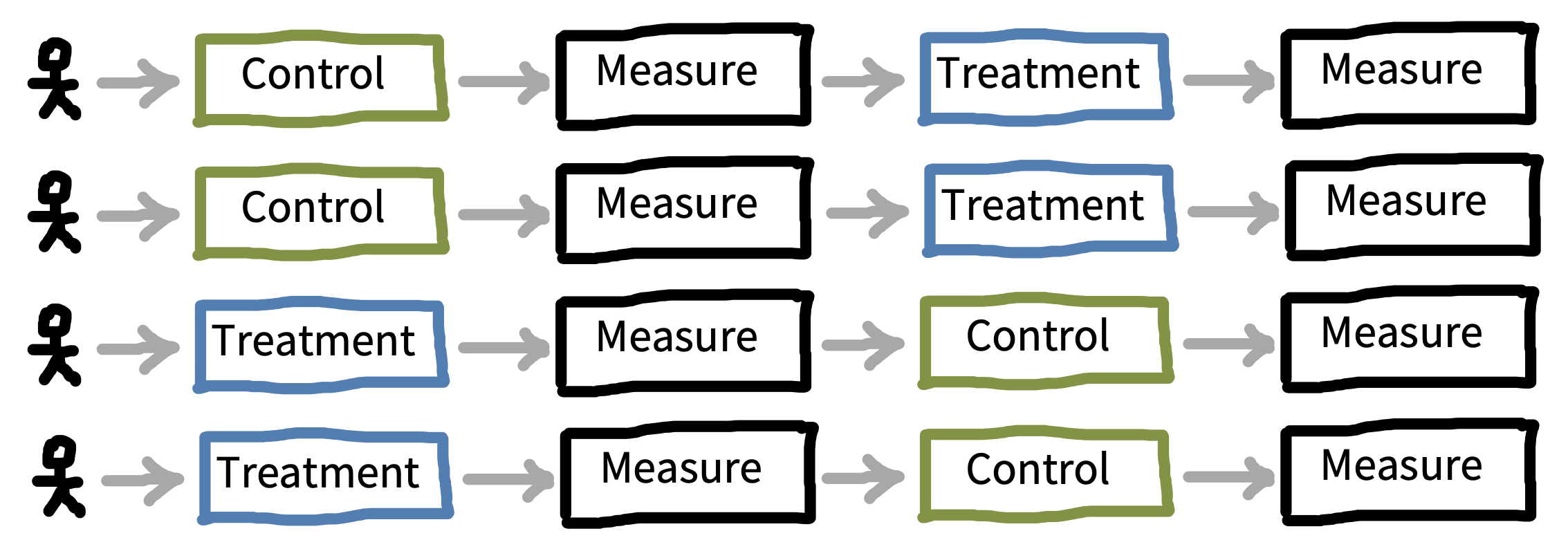
Because people are very variable, the decision whether to measure a particular factor between- or within-participants is consequential. Imagine we’re estimating our treatment effect as before, simply by computing \(\widehat{\beta} = \widehat{\theta}_{T} - \widehat{\theta}_{C}\) with each of these estimates from different populations of participants. In this scenario, our estimate \(\widehat{\beta}\) contains three components: (1) the true differences between \(\theta_{T}\) and \(\theta_{C}\), (2) sampling-related variation in which participants from the population ended up in the samples for the two conditions, and (3) measurement error. Component 2 is present because any two samples of participants from a population will differ in their average on a measure—this is precisely the kind of sampling variation we saw in the null distributions in chapter 6.
When our experimental design is within participants, component 2 is not present because participants in both conditions are sampled from the same population. If we get unlucky and all of our participants are lower than the population mean on our measure, then that unluckiness affects our conditions equally. The consequences for choosing an appropriate sample size are fairly extreme: between-participants designs typically require between two and eight times as many participants as within-participants designs!7
7 If you want to estimate how big an advantage you get from within-participants data collection, you need to know how correlated (reliable) your observations are. One analysis of this issue (Lakens 2016) suggests that the key relationship is \(N_{\text{within}} = N_{\text{between}} (1-\rho) /2\), where \(\rho\) is the correlation between the measurement of the two conditions within individuals. The more correlated they are, the smaller the within-participants \(N\).
Given these advantages, why would you consider using a between-participants design? A within-participants design is simply not possible for all experiments. For example, consider a medical intervention—say, a new surgical procedure that is being compared to an established one. Patients cannot receive two different procedures, and so no within-participant comparison is possible.
Most manipulations in the behavioral sciences are not so extreme, but it still may be impractical or inadvisable to deliver multiple conditions. Greenwald (1976) distinguishes three types of undesirable effects:8
8 We tend to think of all of these as being forms of carryover effect, and sometimes use this label as a catch-all description. Some people also use the picturesque description “poisoning the well” (Gelman 2017)—earlier conditions “ruin” the data for later conditions.
- Practice effects occur when administering the measure or the treatment will lead to change. Imagine a curriculum intervention for teaching a math concept—it would be hard to convince a school to teach the same topic to students twice, and the effect of the second round of teaching would likely be quite different than the first!
- Sensitization effects occur when seeing two versions of an intervention mean that you might respond differently to the second than the first because you have compared them and noticed the contrast. Consider a study on room lighting—if the experimenters are constantly changing the lighting, participants may become aware that lighting is the focus of the study!
- Carryover effects refer to the case where one treatment might have a longer-lasting effect than the measurement period. For example, imagine a study in which one treatment was to make participants frustrated with an impossible puzzle; if a second condition were given after this first one, participants might still be frustrated, leading to spillover of effects between conditions.
All of these issues can lead to real concerns with within-participant designs. But the desire for effect estimates that are completely unbiased by these concerns may lead to the overuse of between-participant designs (Gelman 2017). As mentioned above, between-participant designs come at a major cost in terms of power and precision.
An alternative approach is to acknowledge the possibility of carryover type effects and seek to mitigate them. First, you can make sure that the order of condition is randomized or balanced (see below); and second, you can analyze these carryover effects within your statistical model (for example by estimating the interaction of condition and order).9
9 Even when one factor must be varied between participants, it is often still possible to vary others within subjects, leading to a mixed design in which some factors are between and others within.
10 Caveat: the study design was observational, so no causal inference is possible.
We summarize the state of affairs from our perspective in figure 9.7. We think that within-participant designs should be preferred whenever possible. This conclusion is also consistent with meta-research we’ve done on replications from our course: across 176 student replications, the use of a within-subjects design was the strongest correlate of a successful replication (Boyce, Mathur, and Frank 2023).10

9.1.4 Repeated measures and experimental items
We just discussed decision-making about whether to administer multiple manipulations to a single participant. An exactly analogous decision comes up for measures! And our take-home will be similar: unless there are specific difficulties that come up, it’s usually a very good idea to make multiple measurements (via multiple experimental trials) for each participant in each condition.
You can create a between-participants design where you administer your manipulation and then measure multiple times. This scenario is pictured in figure 9.8. Sometimes this works quite well. For example, imagine a transcranial magnetic stimulation (TMS) experiment: participants receive neural stimulation for a period of time, targeted at a particular region. Then they perform some measurement task repeatedly until it wears off. The more times they perform the measurement task, the better the estimate of whatever effect (when compared to a control of TMS to another region, say).
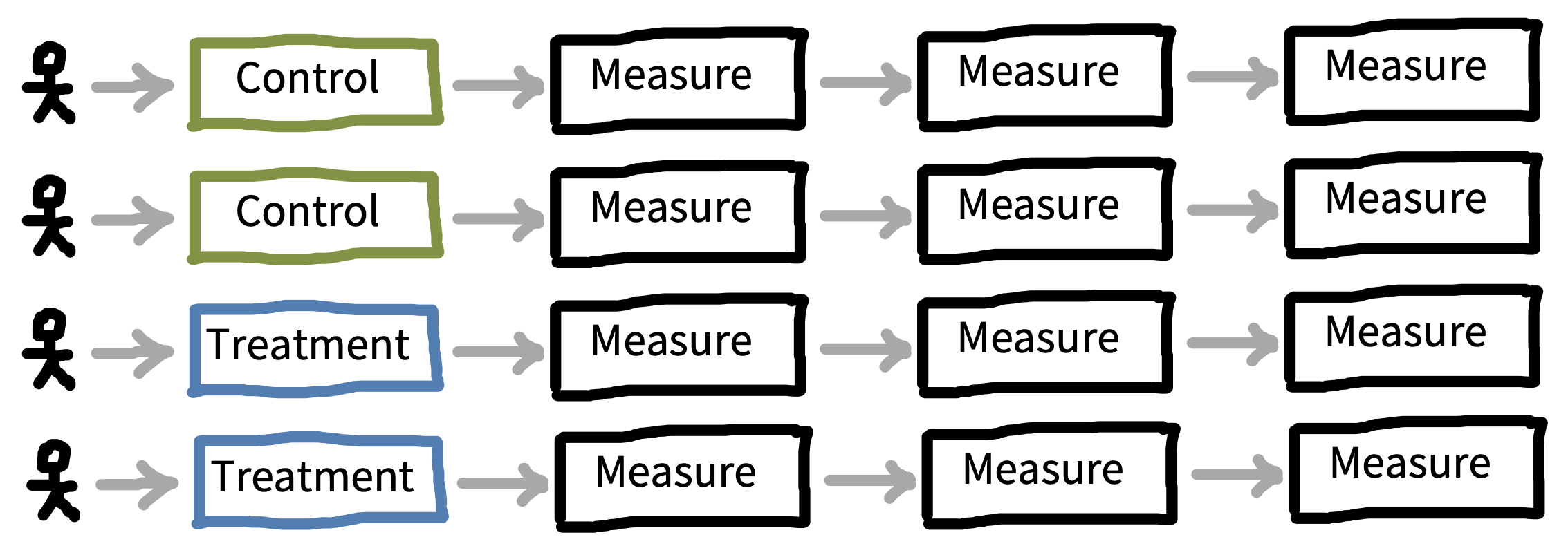
Sometimes this design is called a repeated measures design, but terminology here is tricky again. The term “repeated measures” refers to any experiment where each participant is measured more than once, including both between-participants and within-participants designs.11 Our advice is both to use within-participants designs and to get multiple measurements from each participant.
11 We’re talking about multiple trials with the same measure, not multiple distinct measures. As we discussed in chapter 8, we tend to be against measuring lots of different things in a single experiment—in part because of the concerns that we’re articulating in this chapter: if you have time, it’s better to make more precise measures of what you care about most. Measuring one thing well is hard enough. Much better to measure one thing well than many things badly.
Why? In the last subsection, we described how variability in our estimates in a between-participants design depends on three components: (1) true condition differences; (2) sampling variation between conditions; and (3) measurement error.
Within-participants designs are good because they don’t include (2). Repeated measures reduce (3): the more times you measure, the lower your measurement error, leading to greater measure reliability!
There are problems with repeating the same measure many times, however. Some measures can’t be repeated without altering the response. To take an obvious example, we can’t give the exact same math problem twice and get two useful measurements of mathematical ability! The typical solution to this problem is to create multiple items. In the case of a math assessment, you create multiple problems that you believe test the same concept but have different numbers or other superficial characteristics.
Using multiple items for measurement is good for two reasons. First, it reduces measurement error by allowing responses to be combined across items. But second, it increases the generalizability of the measurement. An effect that is consistent across many different items is more likely to be an effect that can be generalized to a whole class of stimuli—in precisely the same way that the use of multiple participants can license generalizations across a population of people (Clark 1973).
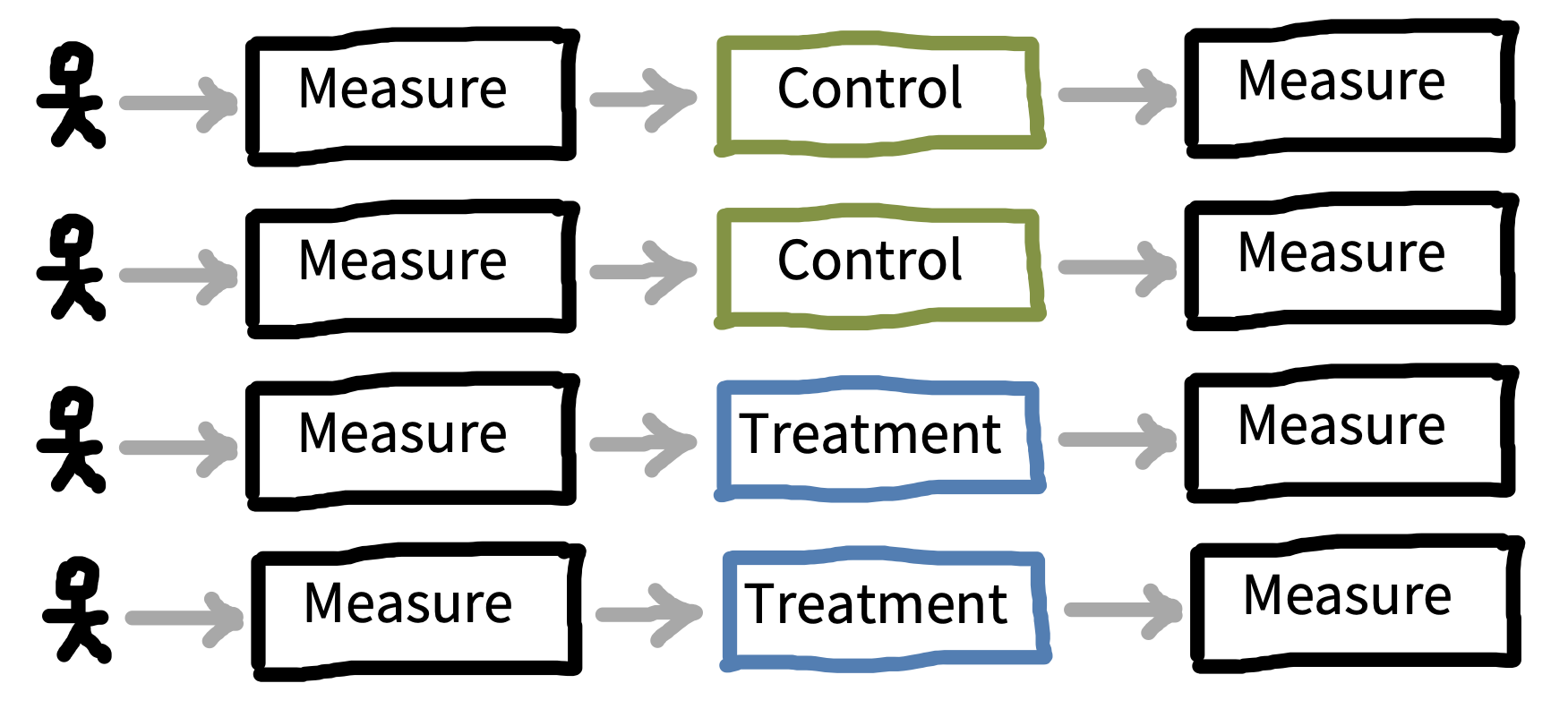
One variation on the repeated measures, between-participants design is a specific version where the measure is administered both before (pre-) and after (post-) intervention, as in figure 9.9. This design is sometimes known as a pre-post design. It is extremely common in cases where the intervention is larger scale and harder to give within-participants, such as in a field experiment where a policy or curriculum is given to one sample and not to another. The premeasurements can be used to subtract out participant-level variability and recover a more precise estimate of the treatment effect. Recall that our treatment effect in a pure between-participants design is \(\beta = \theta_{T} - \theta_{C}\). In a pre-post design, we can do better by computing \(\beta = (\theta_{T_{\text{post}}} - \theta_{T_{\text{pre}}}) - (\theta_{C_{\text{post}}} - \theta_{C_{\text{pre}}})\). This equation says, “How much more did the treatment group go up than the control group?12
12 This estimate is sometimes called a “difference in differences.” The basic idea is widely used in the field of econometrics, both in experimental and quasi-experimental cases (Cunningham 2021). In practice, though, we recommend using the pre-treatment measurements as a covariate in a model-based analysis, not just doing the simple subtraction.
In sum, within-participants, repeated-measurement designs are the bread and butter of most research in perception, psychophysics, and cognitive psychology. When both manipulations and measures can be repeated, these designs afford high measurement precision even with small sample sizes; they are recommended whenever possible.
Stimulus-specific effects
Imagine you’re a psycholinguist who has the hypothesis that nouns are processed faster than verbs. You run an experiment where you pick out ten verbs and ten nouns, then measure a large sample of participants’ reading time for each of these. You find strong evidence for the predicted effect and publish a paper on your claim. The only problem is that, at the same time, someone else has done exactly the same study—with different nouns and verbs—and published a paper making the opposite claim. When this happens, it is possible that each effect is driven by the specific experimental items that were chosen, rather than a generalization that is true of nouns and verbs in general (Clark 1973).
The problem of generalization from sample to population is not new—as we discussed in chapter 6, we are constantly making this kind of inference with the samples of people that participate in our experiments. Our classic statistical techniques are designed to quantify our ability to generalize from a sample of participants to a population, so we recognize that a very small sample size leads to a weak generalization. The exact same issue comes up with items: a very small sample of experimental items leads to a weak generalization to the population of items.
Item effects are kind of like accidentally finding a group of ten people whose left toes are longer than their right ones. If you continued to measure the same group’s toes, you could continue to replicate the difference in length. But that doesn’t mean it’s true of the population as a whole.
This kind of stimulus generalizability problem comes up across many different areas of psychology. In one example, hundreds of papers were written about a phenomenon called the “risky shift”—in which groups deliberating about a decision would produce riskier decisions than individuals. Unfortunately, this phenomenon appeared to be completely driven by the specific choice of vignettes that groups deliberated about, with some stories producing a risky shift and others producing a more conservative shift (Westfall, Judd, and Kenny 2015).
Another example comes from the memory literature, where in a classic paper, Baddeley, Thomson, and Buchanan (1975) suggested that words that take longer to pronounce (“tycoon” or “morphine”) would be remembered worse than words that took a shorter amount of time (“ember” or “wicket”) even when they had the same number of syllables. This effect also appears to be driven by the specific sets of words chosen in the original paper. It’s very replicable with that particular stimulus set but not generalizable to other sets (Lovatt, Avons, and Masterson 2000).
The implication of these examples is clear: experimenters need to take care in both their experimental design and analysis to avoid overgeneralizing from their stimuli to a broader construct. Three primary steps can help experimenters avoid this pitfall:
- To maximize generality, use samples of experimental items—words, pictures, or vignettes—that are comparable in size to your samples of participants.
- When replicating an experiment, consider taking a new sample of items as well as a new sample of participants. It’s more work to draft new items, but it will lead to more robust conclusions.
- When experimental items are sampled at random from a broader population, use a statistical model that includes this sampling process (e.g., mixed effects models with random intercepts for items from chapter 7).
9.1.5 Discrete and continuous experimental manipulations
Most experimental designs in psychology use discrete condition manipulations: treatment vs control. In our view, this decision often leads to a lost opportunity relative to a more continuous manipulation of the strength of the treatment. The goal of an experiment is to estimate a causal effect; ideally, this estimate can be generalized to other contexts and used as a basis for theory. Measuring not just one effect but instead a dose-response relationship—how the measure changes as the strength of the manipulation is changed—has a number of benefits in helping to achieve this goal.
Many manipulations can be titrated—that is, their strength can be varied continuously—with a little creativity on the part of an experimenter. A curriculum intervention can be applied at different levels of intensity, perhaps by changing the number of sessions in which it is taught. For a priming manipulation, the frequency or duration of prime stimuli can be varied. Two stimuli can be morphed continuously so that categorization boundaries can be examined.13
13 These methods are extremely common in perception and psychophysics research, in part because the dimensions being studied are often continuous in nature. It would be basically impossible to estimate a participant’s visual contrast sensitivity without continuously manipulating the contrast of the stimulus!
Dose-response designs are useful because they provide insight into the shape of the function mapping your manipulation to your measure. Knowing this shape can inform your theoretical understanding! Consider the examples given in figure 9.10.
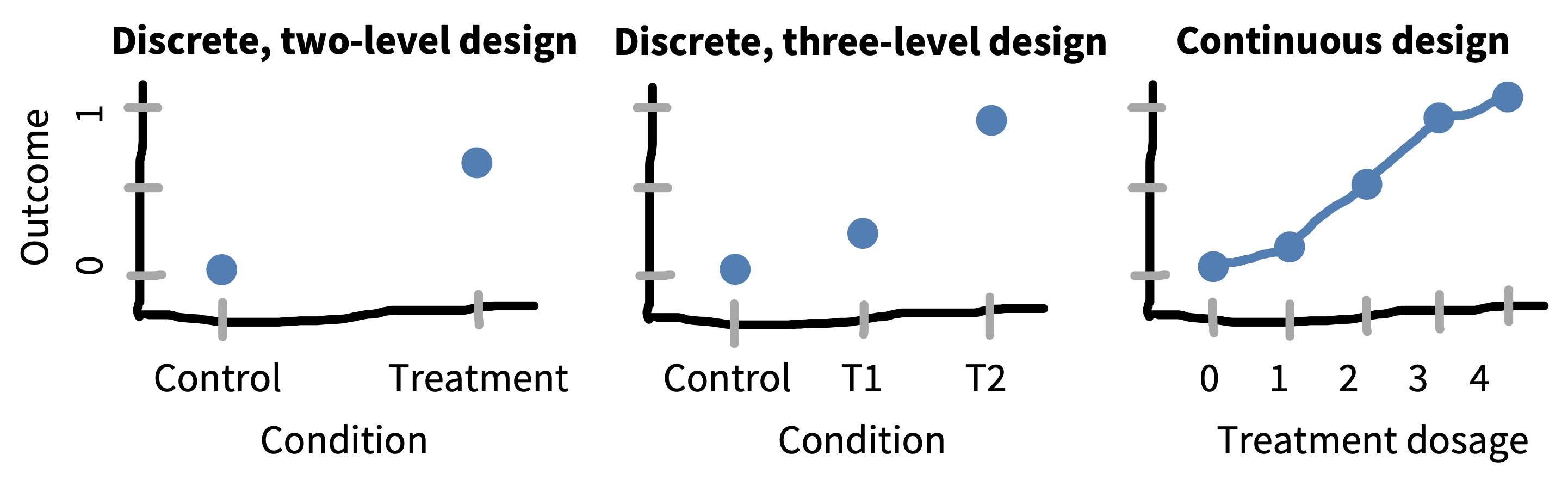
If you only have two conditions in your experiment, then the most you can say about the relationship between your manipulation and your measure is that it produces an effect of a particular magnitude; in essence, you are assuming that condition is a nominal variable. If you have multiple ordered levels of treatment, you can start to speculate about the nature of the relationship between treatment and effect magnitude. But if you can measure the strength of your treatment, then you can begin to describe the nature of the relationship between the strength of treatment and strength of effect via a parametric function (e.g., a linear regression, a sigmoid, or other function).14 These parametric functions can in turn allow you to generalize from your experiment, making predictions about what would happen under intervention conditions that you didn’t measure directly!
14 These assumptions are theory-laden, of course—the choice of a linear function or a sigmoid is not necessary: nothing guarantees that simple, smooth, or monotonic functions are the right ones. The key is that choosing a function makes explicit your assumptions about the nature of the treatment-effect relationship.
Trade-offs associated with titrated designs
Like adults, babies like to look at more interesting, complex stimuli. But do they always prefer complex stimuli, or do they search for stimuli at an appropriate level of complexity for their processing abilities? To test this hypothesis, Brennan, Ames, and Moore (1966) exposed infants in three different age groups (3, 8, and 14 weeks, \(N = 30\)) to black and white checkerboard stimuli with three different levels of complexity (2 x 2, 8 x 8, and 24 x 24).
Their findings are plotted in figure 9.11: the youngest infants preferred the simplest stimuli, while infants at an intermediate age preferred stimuli of intermediate complexity, and the oldest infants preferred the most complex stimuli. These findings help to motivate the theory that infants attend preferentially to stimuli that provide appropriate learning input for their processing ability (Kidd, Piantadosi, and Aslin 2012).

If your goal is simply to detect whether an effect is zero or nonzero, then dose-response designs do not achieve the maximum statistical power. For example, if Brennan, Ames, and Moore (1966) simply wanted to achieve maximal statistical power, they probably should have only tested two age groups and two levels of complexity (say, 3 and 14 week infants and 2 x 2 and 24 x 24 checkerboards). That would have been enough to show an interaction of complexity and age, and their greater resources devoted to these four (as opposed to nine) conditions would mean more precise estimates of each. But their findings would be less clearly supportive of the view that infants prefer stimuli that are appropriate to their processing ability, because no group would have preferred an intermediate level of complexity (as the 8-week-olds apparently did). By seeking to measure intermediate conditions, they provided a stronger test of their theory.
9.2 Choosing your manipulation
In the previous section, we reviewed a host of common experimental designs. These designs provide a palette of common options for combining manipulations and measures. But your choice must be predicated on the specific manipulation you are interested in! In this section, we discuss considerations for experimenters as they design manipulations.
In chapter 8, we talked about measurement validity, but the idea of validity concept can be applied to manipulations as well as measures. In particular, a manipulation is valid if it corresponds to the construct that the experimenter intends to intervene on. In this context, internal validity threats to manipulations tend to refer to cases where factors in the experimental design keep the intended manipulation from actually intervening on the construct of interest. In contrast, external validity threats to manipulations tend to be cases where the manipulation simply doesn’t line up well with the construct of interest.
9.2.1 Internal validity threats: Confounding
First and foremost, manipulations must actually manipulate the construct whose causal effect is being estimated. If they actually manipulate something else instead, they are confounded. This term is used widely in psychology, but it’s worth revisiting what it means. An experimental confound is a variable that is created in the course of the experimental design that is both causally related to the predictor and potentially also related to the outcome. As such, it is a threat to internal validity.
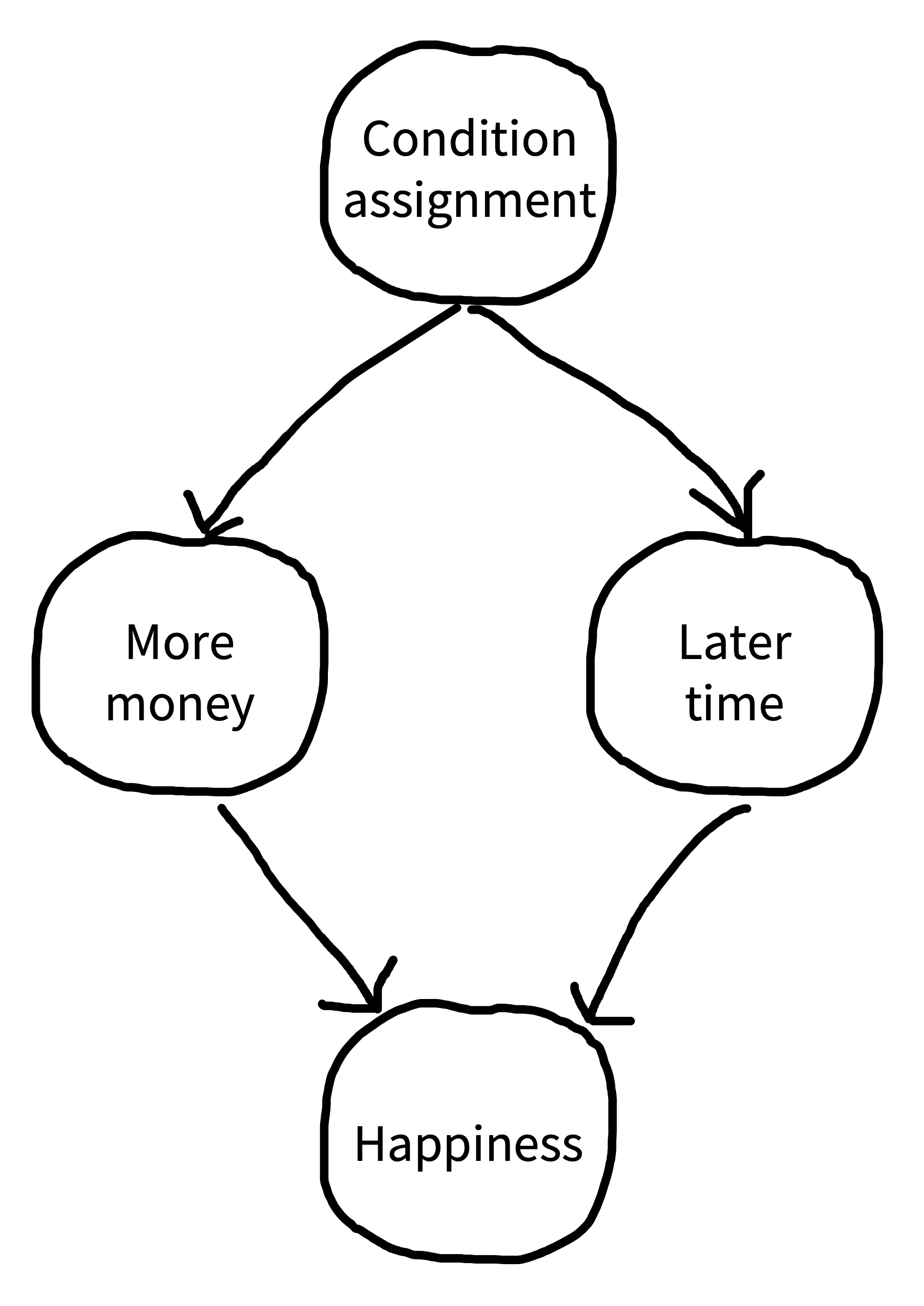
Let’s go back to our discussion of causal inference in chapter 1. Our goal was to use a randomized experiment to estimate the causal effect of money on happiness. But just giving people money is a big intervention that involves contact with researchers—contact alone can lead to an experimental effect even if your manipulation fails. For that reason, many studies that provide money to participants either give a small amount of money or a large amount of money. This design keeps researcher contact consistent in both conditions, implying that the difference in outcomes between these two conditions should be due to the amount of money received (unless there are other confounds!).
Suppose you were designing an experiment of this sort and you wanted to follow our advice and use a within-participants design. You could measure happiness, give participants $100, wait a month and measure happiness again, give participants $1,000, wait a month, and then measure happiness for the third time. The trouble is, this design has an obvious experimental confound (figure 9.12): the order of the monetary gifts. Maybe happiness just went up more over time, irrespective of getting the second gift.
If you think your experimental design might have a confound, you should think about ways to remove it. A first option is elimination, which we described above: basically, matching a particular variable across different conditions. This should be our first option for most confounds. Unfortunately, in our within-participants money-happiness study, order is confounded with condition so if we match orders we have eliminated our condition manipulation entirely.
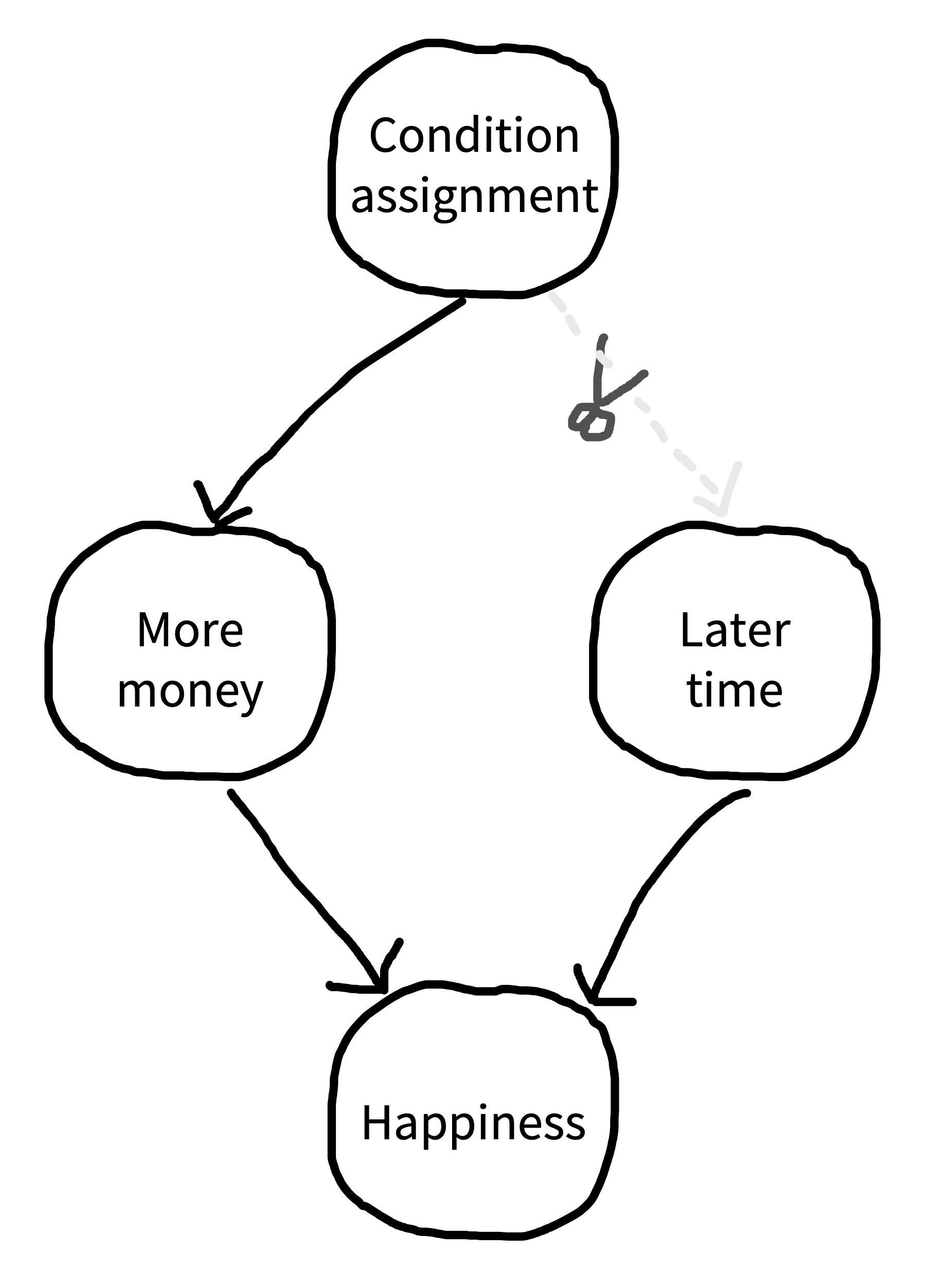
A second option is counterbalancing, in which we vary a confounding factor systematically across participants so its average effect is zero across the whole experiment. In the case of our example, counterbalancing order across participants is a very safe choice. Some participants get $100 first and others get $1,000 first. That way, you are guaranteed that the order of conditions will have no effect of the confound on your average effect. The effect of this counterbalancing is that it “snips” the causal dependency between condition assignment and later time. We notate this on our causal diagram with a scissors icon (figure 9.13).15 Time can still have an effect on happiness, but the effect is independent from the effect of condition and, hence, your experiment can still yield an unbiased estimate of the condition effect.
15 In practice, counterbalancing is like adding an additional factor to your factorial design! But because the factor is a nuisance factor—basically, one we don’t care about—we don’t discuss it as a true condition manipulation. Despite that, it’s a good practice to check for effects of these sorts of nuisance factors in your preliminary analysis. Even though your average effect won’t be biased by it, it introduces variation that you might want to understand to interpret other effects and plan new studies.
Counterbalancing gets trickier when you have too many levels on a variable or multiple confounding variables. In that case, it may not be possible to do a full counterbalance so that all combinations of these factors are seen by equal numbers of participants. You may have to rely on partial counterbalancing schemes or Latin square designs (see the Depth box above; in this case, the Latin squares are used to create orderings of stimuli such that the position of each treatment in the order is controlled across two other confounding variables).
A final option, especially useful for such tricky cases, is randomization—that is, choosing which level of a nuisance variable to administer to the participant via a random choice. Randomization is increasingly common now that many experimental interventions are delivered by software. If you can randomize experimental confounds, you probably should. The only time you really get in trouble with randomization is when you have a large number of options, a small number of participants, or some combination of the two. Then you can end up with unbalanced levels of the randomized factors. Averaging across many experiments, a lack of balance will come out in the wash, but in a single experiment, it can lead to unfortunate bias in numbers.
A good approach to thinking through your experimental design is to walk through the experiment step by step and think about potential confounds. For each of these confounds, consider how it might be removed via counterbalancing or randomization. As our case study shows, confounds are not always obvious, especially in complex paradigms. There is no sure-fire way to ensure that you have spotted every one—sometimes the best way to avoid them is simply to present your candidate design to a skeptical friend.
9.2.2 Internal validity threats: Placebo, demand, and expectancy
A second class of important threats to internal validity comes from cases where the research design is confounded by factors related to how the manipulation is administered, or even that a manipulation is administered. In some cases, these create confounds that can be controlled; in others they must simply be understood and guarded against. Rosnow and Rosenthal (1997) called these “artifacts”: systematic errors related to research on people, conducted by people.
A placebo effect is a positive effect on the measure that comes as a result of participants’ expectations about a treatment in the context of a research study. The classic example of a placebo is medical: giving an inactive sugar pill as a “treatment” leads some patients to report a reduction in whatever symptom they are being treated for. Placebo effects are a major concern in medical research as well as a fixture in experimental designs in medicine (Benedetti 2020). The key insight is that treatments must not simply be compared to a baseline of no treatment but rather to a baseline in which the psychological aspects of treatment are present but the “active ingredient” is not. In the terms we have been using, the experience of receiving a treatment (independent of the content of the treatment) is a confounding factor when you simply compare treatment to no treatment conditions.
Brain training?
Can doing challenging cognitive tasks make you smarter? In the late 2000s and early 2010s, a large industry for “brain training” emerged. Companies like Lumos Labs, CogMed, BrainHQ, and CogniFit offered games, often modeled on cognitive psychology tasks, that claimed to lead to gains in memory, attention, and problem-solving.
These companies were basing their claims in part on a scientific literature reporting that concerted training on difficult cognitive tasks could lead to benefits that transferred to other cognitive domains. Among the most influential of these was a study by Jaeggi et al. (2008). They conducted four experiments in which participants (\(N = 70\) across the studies) were assigned to either working memory training via a difficult working memory task (the “dual N-back”) or a no-training control, with training varying from eight days all the way to 19 days.
The finding from this study excited a tremendous amount of interest because they reported gains in performance not only on the specific training task but also on a general intelligence task that the participants hadn’t trained on. While the control group’s scores on these tasks improved, presumably just from being tested twice, there was a condition by time (pre-test vs post-test) interaction such that the scores of the trained groups (consolidated across all four training experiments) grew significantly more over the training period (figure 9.14). These results were interpreted as supporting transfer—whereby training on one task leads to broader gains—a key goal for “brain training.”
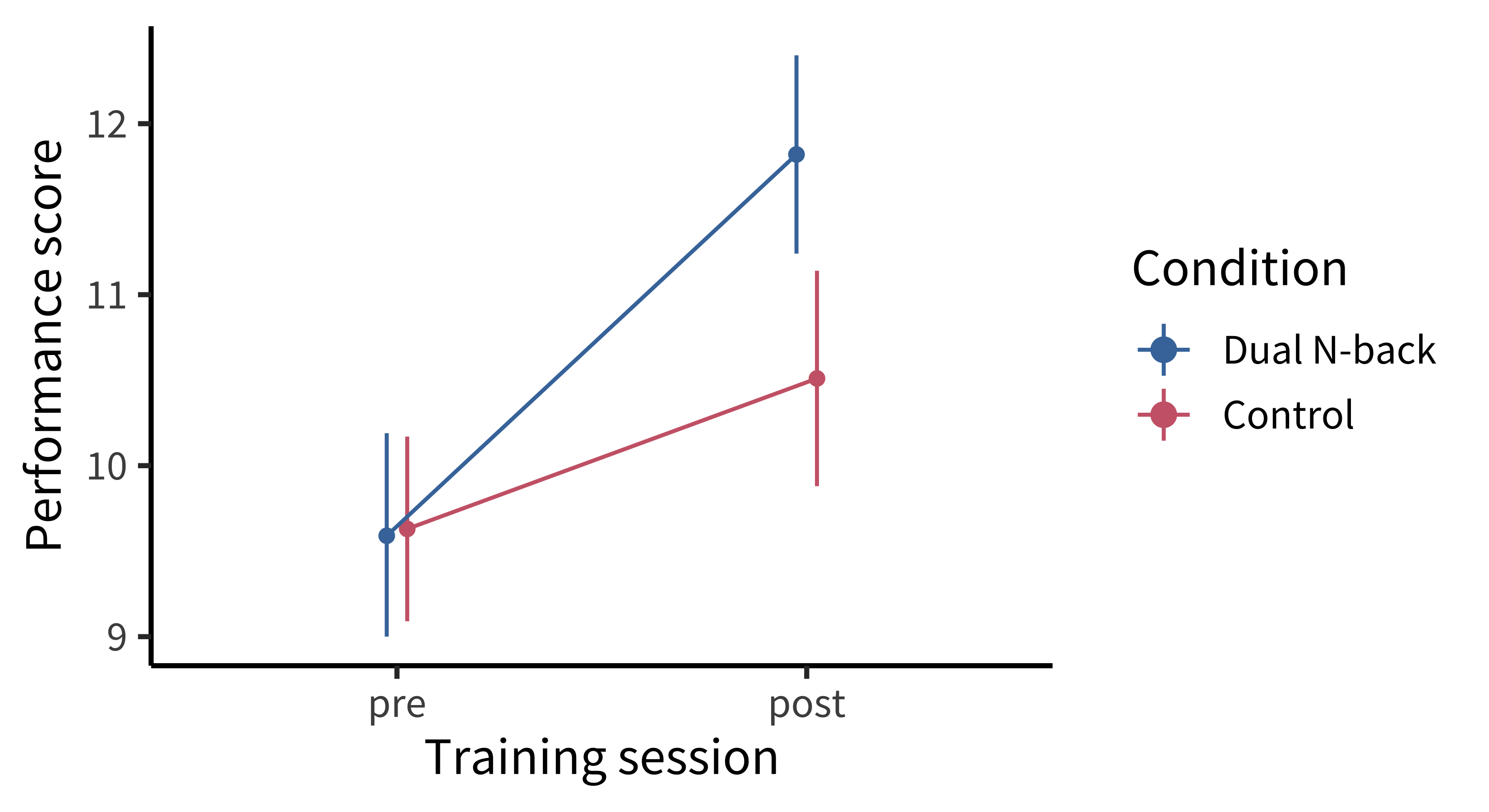
Careful readers of the original paper noticed signs of analytic flexibility (as discussed in chapters 3 and 6), however. For example, the key statistical model was fit to dataset created by post hoc consolidation of experiments, which yielded \(p = 0.025\) on the key interaction (Redick et al. 2013). When data were disaggregated, it was clear that the measures and effects had differed in each of the different subexperiments (figure 9.15).
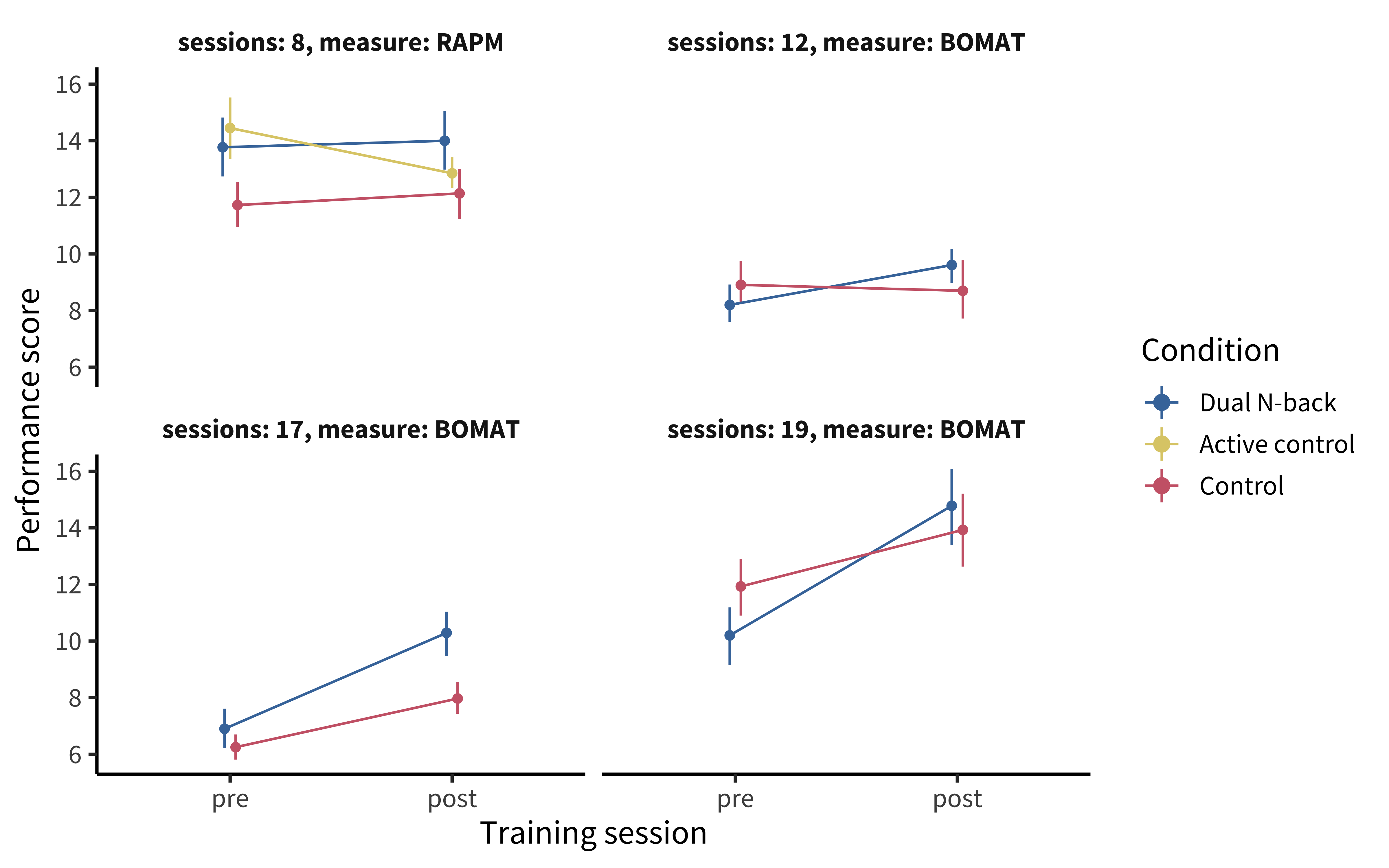
Several replications by the same group addressed some of these issues, but they still failed to show convincing evidence of transfer. In particular, there was no comparison to an active control group in which participants did some kind of alternative activity for the same amount of time (Simons et al. 2016). Such a comparison is critical because a comparison to a passive control group (a group that does no intervention) confounds participants’ general effort and involvement in the study with the specific training being used. Successful transfer compared to passive control could be the result of participants’ involvement, expectations, or motivation rather than the training per se.
A careful replication of the training study (\(N = 74\)) with an active control group and a wide range of outcome measures failed to find any transfer effects from working-memory training (Redick et al. 2013). A meta-analysis of 23 studies concluded that their findings cast doubt on working memory training for increasing cognitive functioning (Melby-Lervåg and Hulme 2013). In one convincing test of the cognitive transfer theory, a BBC show (“Bang Goes the Theory”) encouraged its listeners to participate in a six-week online brain-training study. More than 11,000 listeners completed the pre- and post-tests and at least two training sessions. Neither focused training of planning and reasoning nor broader training on memory, attention, and mathematics led to transfer to untrained tasks.
Placebo effects are one plausible explanation for some positive findings in the brain-training literature. Foroughi et al. (2016) recruited participants to participate via two different advertisements. The first advertised that “numerous studies have shown working memory training can increase fluid intelligence” (“placebo treatment” group), while the second simply offered experimental credits (control group). After a single training session, the placebo treatment group showed significant improvements to their matrix reasoning abilities. Participants in the placebo treatment group realized gains from training out of proportion with any they could have realized through training. Further, those participants who responded to the placebo treatment ad tended to endorse statements about the malleability of intelligence, suggesting that they might have been especially likely to self-select into the intervention.
Summarizing the voluminous literature on brain training, Simons et al. (2016) wrote: “Despite marketing claims from brain-training companies of ‘proven benefits’ … we find the evidence of benefits from cognitive brain training to be ‘inadequate.’”
If placebo effects reflect what participants expect from a treatment, then demand characteristics reflect what participants think experimenters want and their desire to help the experimenters achieve that goal (Orne 1962). Demand characteristics are often raised as a reason for avoiding within-participants designs—if participants become alert to the presence of an intervention, they may then respond in a way that they believe is helpful to the experimenter. Typical tools for controlling or identifying demand characteristics include using a cover story to mask the purpose of an experiment, using a debriefing procedure to probe whether participants typically guessed the purpose of an experiment, and (perhaps most effectively) creating a control condition with similar demand characteristics but missing a key component of the experimental intervention. Note that if you use a cover story to mask the purpose of your experiment, it’s worth thinking about whether you are using deception, which can raise ethical issues (see chapter 4). Certainly you should be sure to debrief participants about the true function of the experiment!
The final entry into this list of internal validity threats is experimenter expectancy effects, where the experimenter’s behavior biases participants in a way that results in the appearance of condition differences where no true difference exists. The classic example of such effects is from the animal learning literature and the story of Clever Hans. Clever Hans was a horse who appeared able to do arithmetic by tapping out solutions with his hoof. On deeper investigation, it became apparent he was being cued by his trainer’s posture (apparently without the trainer’s knowledge) to stop tapping when the desired answer was reached. The horse knew nothing about math, but the experimenter’s expectations were altering the horse’s behavior across different conditions.
In any experiment delivered by human experimenters who know what condition they are delivering, condition differences can result from experimenters imparting their expectations. Table 9.2 shows the results of a meta-analysis estimating sizes of expectancy effects in a range of domains—the magnitudes are shocking. There’s no question that experimenter expectancy is sufficient to “create” many interesting phenomena artifactually. The mechanisms of expectancy are an interesting research topic in their own right; in many cases expectancies appear to be communicated nonverbally in much the same way that Clever Hans learned (Rosnow and Rosenthal 1997).
| Domain | d | r | Example of type of study |
|---|---|---|---|
| Laboratory interviews | 0.14 | 0.07 | Effects of sensory restriction on reports of hallucinatory experiences |
| Reaction time | 0.17 | 0.08 | Latency of word associations to certain stimulus words |
| Learning and ability | 0.54 | 0.26 | IQ test scores, verbal conditioning (learning) |
| Person perception | 0.55 | 0.27 | Perception of other people’s success |
| Inkblot tests | 0.84 | 0.39 | Ratio of animal to human Rorschach responses |
| Everyday situations | 0.88 | 0.40 | Symbol learning, athletic performance |
| Psychophysical judgments | 1.05 | 0.46 | Ability to discriminate tones |
| Animal learning | 1.73 | 0.65 | Learning in mazes and Skinner boxes |
| Weighted mean | 0.70 | 0.33 | |
| Unweighted mean | 0.74 | 0.35 | |
| Median | 0.70 | 0.33 |
In medical research, the gold standard is an experimental design where neither patients nor experimenters know which condition the patients are in.16 Results from other designs are treated with suspicion because of their vulnerability to demand and expectancy effects. In psychology, the most common modern protection against experimenter expectancy is the delivery of interventions by a computer platform that can give instructions in a coherent and uniform way across conditions.
16 These are commonly referred to as double-blind designs (though the term masked is now often preferred).
In the case of interventions that must be delivered by experimenters, ideally experimenters should be unaware of which condition they are delivering. On the other hand, the logistics of maintaining experimenter ignorance can be quite complicated in psychology. For this reason, many researchers opt for lesser degrees of control: for example, choosing to standardize delivery of an intervention via a script. These designs are sometimes necessary for practical reasons but should be scrutinized closely. “How can you rule out experimenter expectancy effects?” is an uncomfortable question that should be asked more frequently in seminars and paper reviews.
9.2.3 External validity of manipulations
The goal of a specific experimental manipulation is to operationalize a particular causal relationship of interest. Just as the relationship between measure and construct can be more or less valid, so too can the relationship between manipulation and construct. How can you tell? Just like in the case of measures, there’s no one royal road to validity. You need to make a validity argument (Kane 1992).17
17 One caveat is that the validity of a manipulation incorporates the validity of the manipulation and the measure. You can’t have a good estimate of a causal effect if the measurement is invalid.
For testing the effect of money on happiness, our manipulation was to give participants $1,000. This manipulation is clearly face valid. But how often do people just receive a windfall of cash, versus getting a raise at work or inheriting money from a relative? Is the effect caused by having the money, or receiving the money with no strings attached? We’d have to do more experiments to see what aspect of the money manipulation was most important. Even in straightforward cases like this one, we need to be careful about the breadth of the claims we make.
Sometimes validity arguments are made based on the success of the manipulation in producing some change in the measurement. In the implicit theory of mind case study we began with, the stimulus contained an animated Smurf character, and the argument was that participants took the Smurf’s beliefs into account in making their judgments. This stimulus choice seems surprising—not only would participants have to track the implicit beliefs of other people but they would also have to be tracking the beliefs of depictions of nonhuman, animated characters. On the other hand, based on the success of the manipulation, the authors made an a fortiori argument: if people track even an animated Smurf’s beliefs, then they must be tracking the beliefs of real humans.
Let’s look at one last example to think more about manipulation validity. Walton and Cohen (2011) conducted a short intervention in which college students (\(N = 92\)) read about social belonging and the challenges of the transition to college and then reframed their own experiences using these ideas. This intervention led to long-lasting changes in grades and well-being. While the intervention undoubtedly had a basis in theory, part of our understanding of the validity of the intervention comes from its efficacy: sense of belonging must be a powerful factor if intervening on it causes such big changes in the outcome measures.18 The only danger is when the argument becomes circular—a theory is correct because the intervention yielded a success, and the intervention is presumed to be valid because of the theory. The way out of this circle is through replication and generalization of the intervention. If the intervention repeatably produces the outcome, as has been shown in replications of the sense of belonging intervention (Walton, Brady, and Crum 2020), then the manipulation becomes an intriguing target for future theories. The next step in such a research program is to understand the limitations of such interventions (sometimes called boundary conditions).
18 On the other hand, if the manipulation doesn’t produce a change in your measure, maybe the manipulation is invalid, but the construct still exists. Sense of belonging could still be important even if my particular intervention failed to alter it!
9.3 Chapter summary: Experimental design
In this chapter, we started by examining some common experimental designs that allow us to measure effects associated with one or more manipulations. Our advice, in brief, was: “Keep it simple!” The failure mode of many experiments is that they contain too many manipulations, and these manipulations are measured with too little precision.
Start with just a single manipulation and measure it carefully. Ideally this measurement should be done via a within-participants design unless the manipulation is completely incompatible with this design. And if this design can incorporate a dose-response manipulation, it is more likely to provide a basis for quantitative theorizing.
How do you ensure that your manipulation is valid? A careful experimenter needs to consider possible confounds and ensure that these are controlled or randomized. They must also consider other artifacts including placebo, demand, and expectancy effects. Finally, they must begin thinking about the relation of their manipulation to the broader theoretical construct whose causal role they hope to test.
Choose a classic study in your area of psychology. Analyze the design choices: How many factors were manipulated? How many measures were taken? Did it use a within- or between-participants design? Were measures repeated? Can you justify these choices with respect to trade-offs (e.g., carryover effects, fatigue, or others)?
Consider the same study. Design an alternative version that varies one of these design parameters (e.g., drops a manipulation or measure or changes within- to between-participants). What are the pros and cons of this change? Do you think your design improves on the original?
- Much of this material is covered in more depth in the classic text on research methods: Rosenthal, Robert, and Ralph L. Rosnow (2008). Essentials of Behavioral Research: Methods and Data Analysis. Third Edition. McGraw-Hill. http://dx.doi.org/10.34944/dspace/66.